Docker学习笔记
本文最后更新于:3 个月前
Docker
一些前置知识
安装docker
chroot
是在Unix和 Linux系统的一个操作,针对正在运作的软件行程和它的子进程,改变它外显的根目录。一个运行在这个环境下,经由chroot设置根目录的程序,它不能够对这个指定根目录之外的文件进行访问动作,不能读取,也不能更改它的内容。
容器技术原理
chroot
namespace:主机名,网络,PID等资源的隔离
Namespace对内核资源进行隔离,使得容器中的进程都可以在单独的命名空间中运行并且只可以访问当前容器命名空间的资源。
Namespace可以隔离进程ID、主机名、用户ID、文件名、网络访问和进程间通信等相关资源
docker主要用到以下五种命名空间:
- pid namespace:隔离进程ID
- net namespace:隔离网络接口
- mnt namespace:文件系统挂载点隔离
- ipc namespace:信号量,消息队列和共享内存的隔离
- uts namespace:主机名和域名的隔离
cgroup:对进程或进程组做资源的限制
cgroup是一种Linux内核功能,可以限制和隔离进程的资源使用情况(CPU,内存,磁盘IO,网络等)
联合文件系统:用于镜像构建和容器运行环境
又叫UnionFS,是一种通过创建文件层进程操作的文件系统。常用的联合文件系统有AUFS、Overlay和Devicemapper等
问题:容器技术在Docker出现之前一直没有爆发的根本原因??
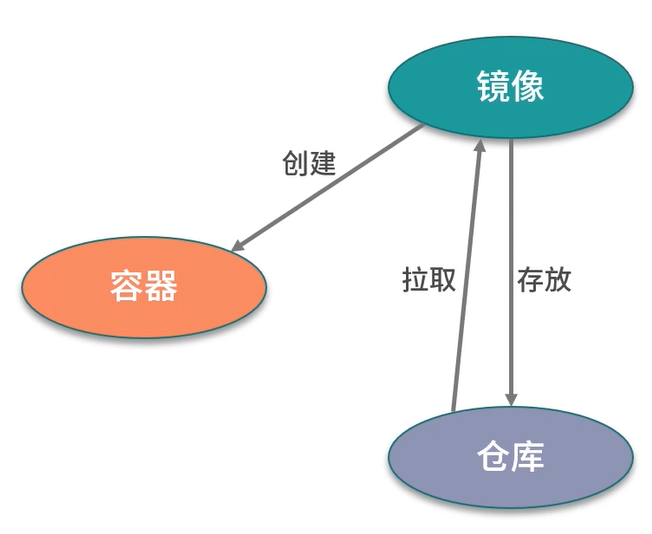
镜像,容器,仓库
镜像:是一个只读的 Docker容器模板,包含启动容器所需要的所有文件系统结构和内容。
镜像是一个特殊的文件系统,它提供了容器运行时所需的程序,软件库,资源,配置等静态数据。镜像不包含任何动态数据,镜像内容在构建后不会被改变。
容器:容器是镜像的运行实体。容器的本质是主机上运行的一个进程,但是容器有自己的命名空间隔离和资源限制。在容器内部,无法看到主机上的进程,环境变量,网络等信息。
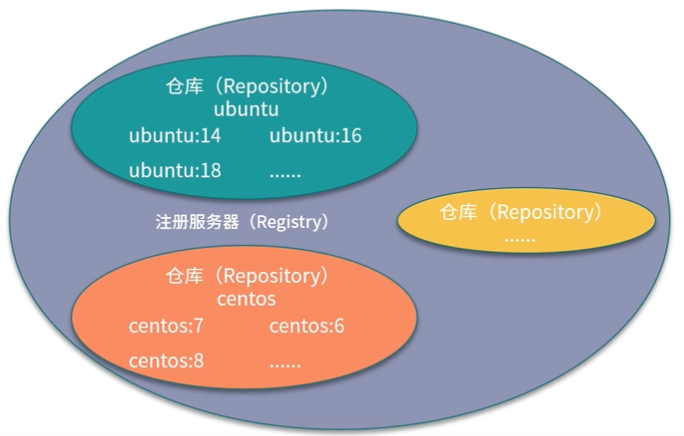
仓库:是存储和分发Docker镜像的地方
- 公共镜像仓库:
- 私有镜像仓库
注册服务器是用来存放仓库的实际服务器,仓库可以被理解为一个具体的项目或者目录
往仓库中推送镜像
1 | |
搭建私有镜像仓库
1 | |
这时,我们就有了一个私有的镜像仓库,ip为localhost,端口号为5000
1 | |
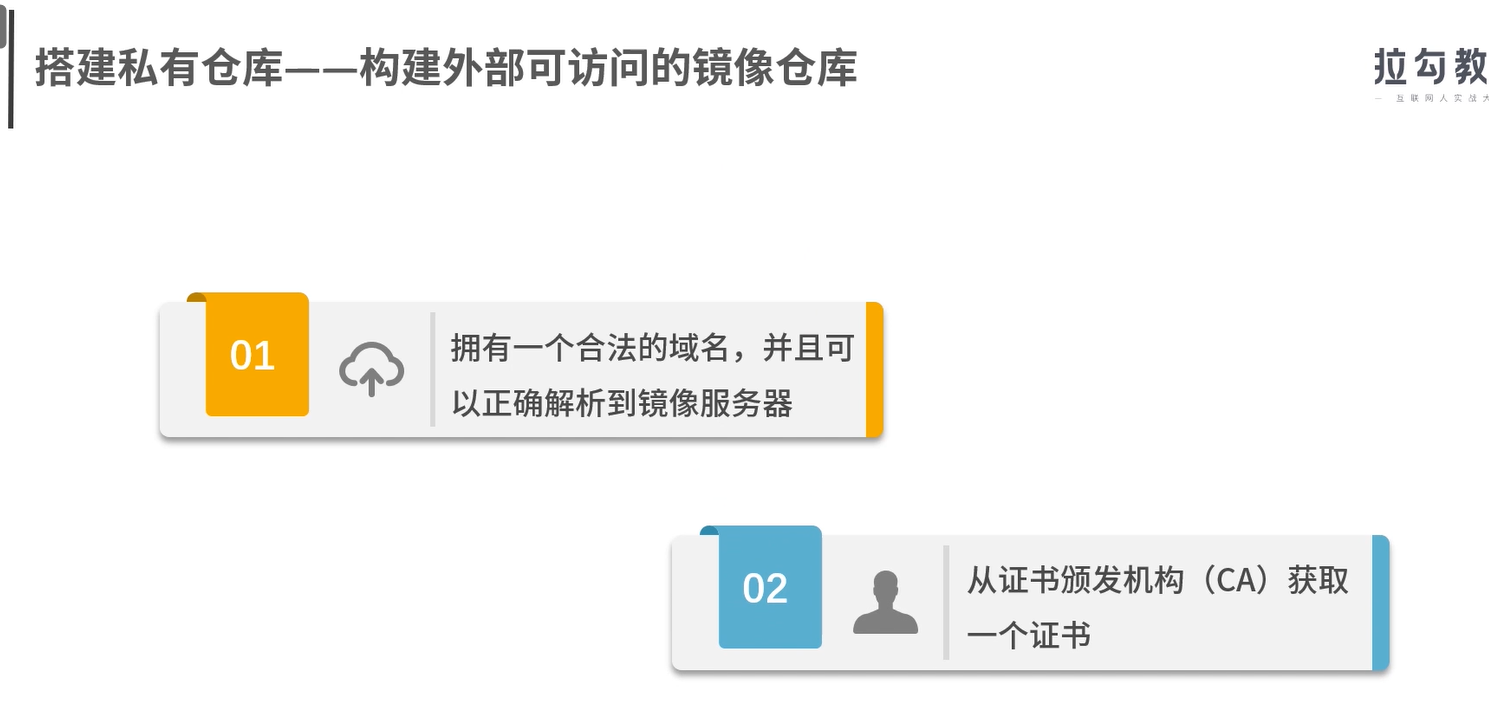
构建外部可以访问的镜像仓库
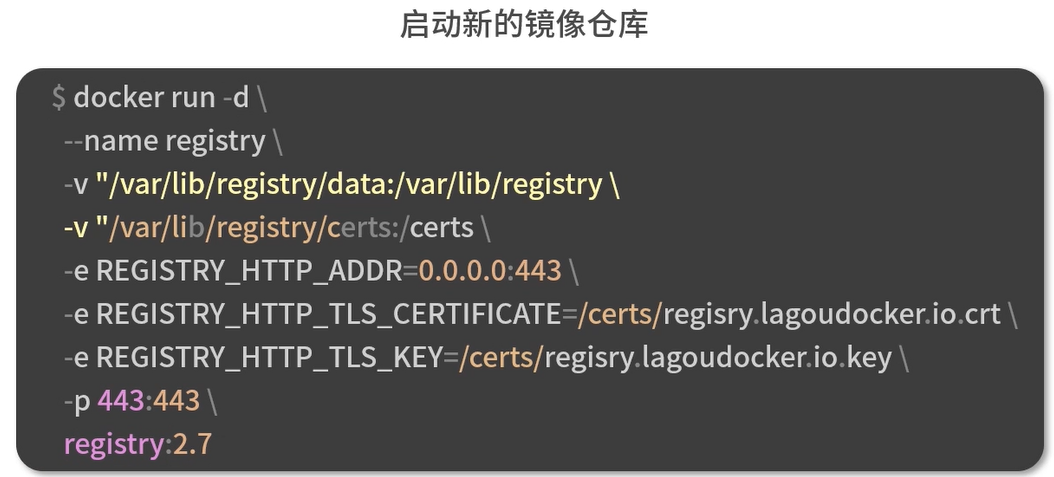


OCI
全称 open container Initiative 开放容器标准,是一个轻量级,开放的治理结构
- 容器运行时标准:runtime spec
- 容器镜像标准:image spec
docker架构
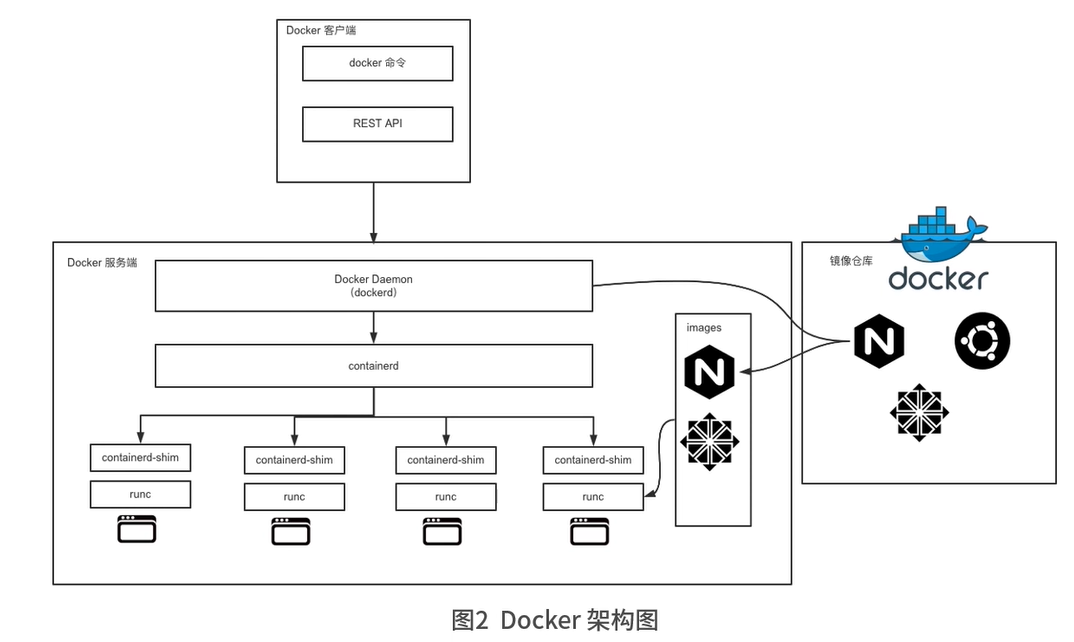
docker客户端与服务器端通信方式:
- 在同一台机器上通过Unix套接字通信
- 通过网络连接远程通信
docker客户端
- docker命令是docker用户与docker客户端进行交互的主要方式
- 使用直接请求REST API的方式与docker服务端交互
- 使用各种语言的SDK与docker服务端交互
docker服务端
- docker服务端是Docker所有后台服务的总称
- dockerd负责响应和处理来自Docker客户端的请求,然后将客户端的请求转化为Docker的具体操作

docker重要组件
- runC:用来运行容器的轻量级工具,是真正用来运行容器的
- containerd:通过container-shim启动并管理runC。containerd真正管理了容器的生命周期。
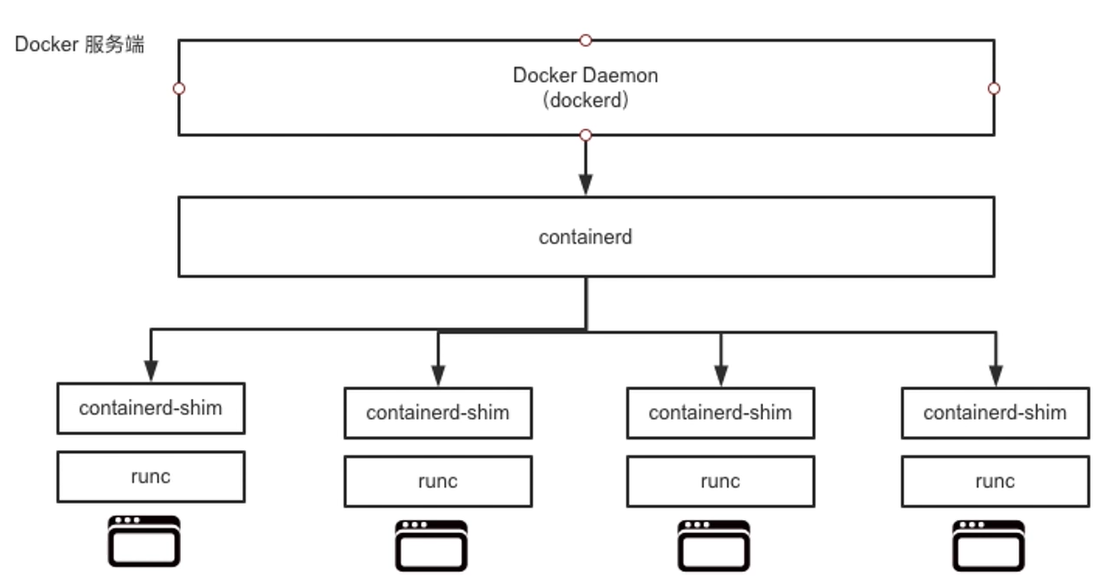
dockerd通过gRPC与containerd通信
一个实例
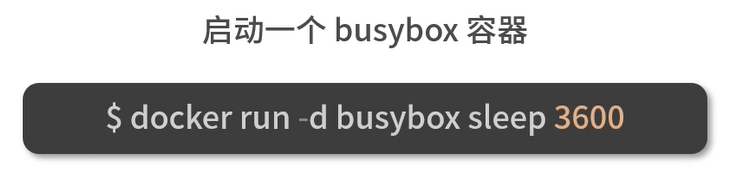

dockerd启动时,containerd就随之启动了,dockerd与containerd一直存在。当执行docker run命令时, containerd会创建containerd-shim充当垫片进程,然后启动容器的真正进程。
镜像操作
查看镜像,并过滤出busybox镜像:docker iamges |grep busybox
经验
默认网络配置
docker若使用默认网络配置bridge,重启一次容器会重新分配ip地址
跨宿主机通信
需要在Docker主机上添加静态路由????
查看docker容器的ip地址
1 | |
这样得到的结果与在docker中使用ifconfig命令得到的结果是一样的
查看所有容器的ip地址
1 | |
docker的ip重启后会发生变化
在docker中,重启后ip是会变的;docker默认采用bridge连接,启动容器的时候会按照顺序来获取对应ip地址,这就导致容器每次重启后ip都会发生变化。
创建自定义网络解决IP不固定的问题
创建自定义网络,指定ip网段
1
2
3
4
5
6
7
8docker network create --subnet=172.20.0.0/16 netsc
(base) sc@NSL-1:/etc/docker$ docker network ls
NETWORK ID NAME DRIVER SCOPE
2076afc0f56f bridge bridge local
1f5f0288ece5 host host local
4bc4edf2b20a netsc bridge local
fed48795e6f5 none null local创建容器时,–net参数采用netsc即可,同时记得配置–ip参数,这样容器重启时其ip也不会变化。
1
docker run -it --net netsc --ip 172.20.0.101 --gpus 'device=0' --name torch0 -v /data/sc:/data fa50f7fed43a
–net
host
WARNING: Published ports are discarded when using host network mode
使用主机网络模式时,run容器时使用的端口映射将被丢弃
相当于VMware 中的桥接模式,与宿主机在同一个网络中,但是没有独立IP地址
Docker 使用了Linux 的Namespace 技术来进行资源隔离,如 PID Namespace 隔离进程,Mount Namespace 隔离文件系统,Network Namespace 隔离网络等。一个Network Namespace 提供了一份独立的网络环境,包括网卡,路由,iptable 规则等都与其他Network Namespace 隔离。一个Docker 容器一般会分配一个独立的Network Namespace。
但是如果启动容器的时候使用host 模式,那么这个容器将不会获得一个独立的Network Namespace ,而是和宿主机共用一个Network Namespace 。容器将不会虚拟出自己的网卡,配置自己的IP等,而是使用宿主机的IP和端口范围。此时容器不再拥有隔离的、独立的网络栈。不拥有端口资源。
bridge
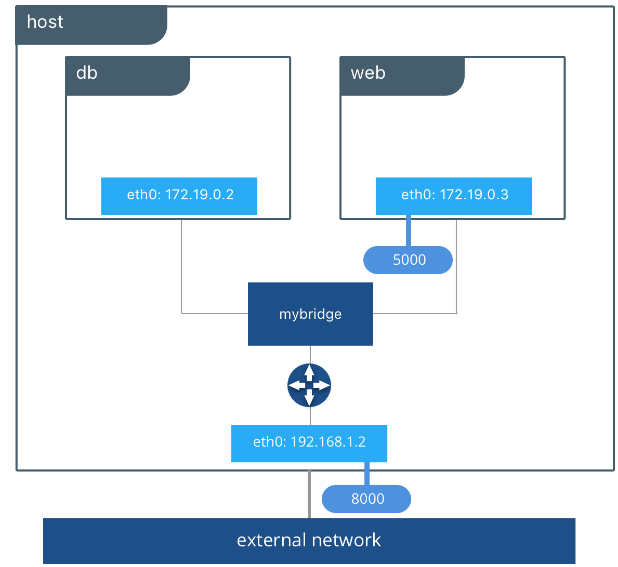
单独容器中的应用通过桥接网络互相通讯,也就是图中的mybridge,在服务器中是docker0,功能类似于一个物理交换机。
镜像命令
docker search hello-world: 在远程仓库查找有没有hello-world这个镜像
docker images : -a 列出所有镜像信息 -q 只列出镜像ID
docker pull 镜像名字 [:TAG] : 从rep拉取镜像
docker system df : 查看镜像、容器、数据卷所占的空间
docker rmi 镜像名字 : 删除 -f 强制删除 可以删除多个镜像 加多个镜像名字或者ID 可以带上:TAG
虚悬镜像 repository仓库名和tag都是< none > 的镜像叫做虚悬镜像
容器是什么
容器是基于镜像创建的可运行实例,并且单独存在。一个镜像可以创建出多个容器。
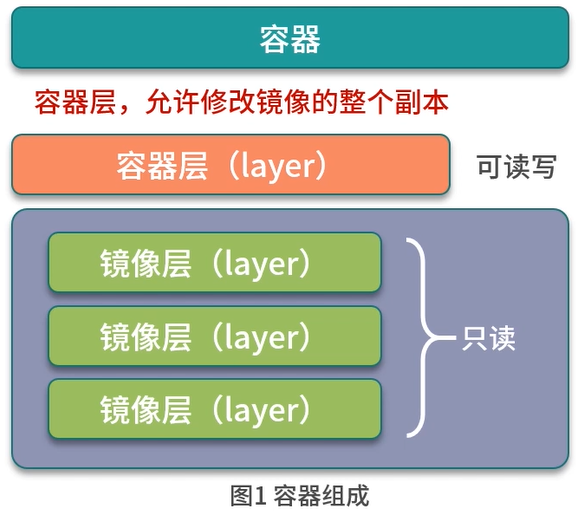
创建容器实际上是在镜像层上创建一个容器层,可读写,允许修改镜像的整个副本。
容器是在镜像的只读层上创建了可写层,并且容器中的进程属于运行状态,容器是真正的应用载体。
容器的生命周期

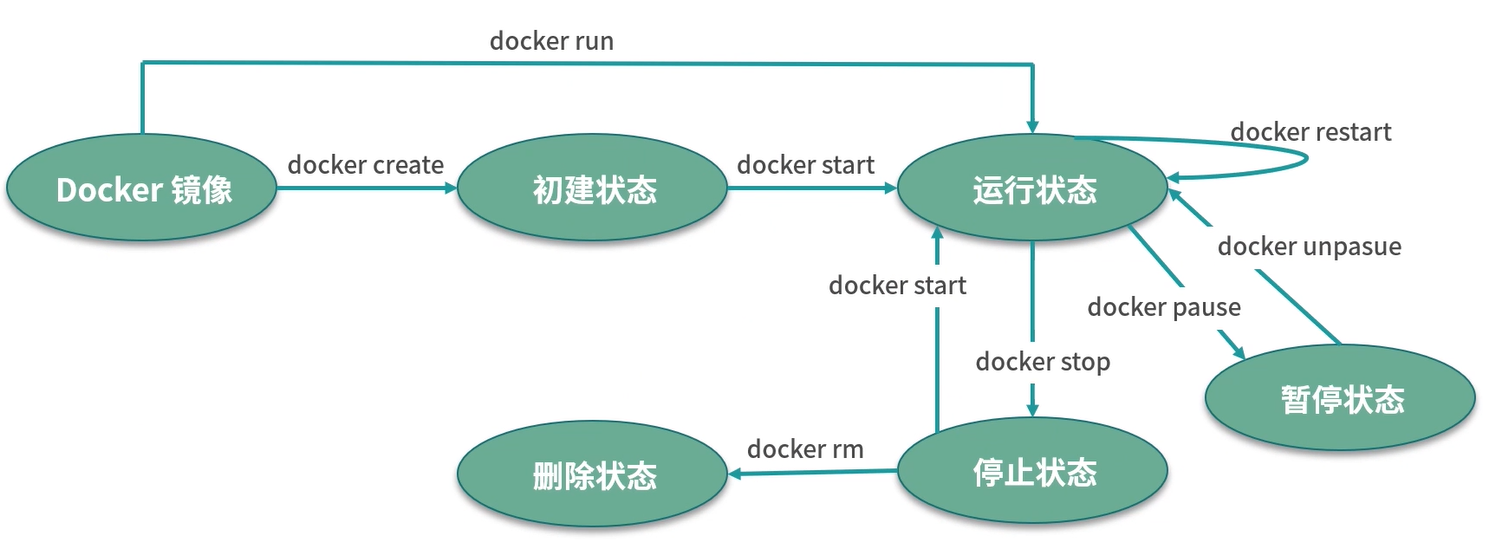
docker run之后Docker的操作
docker run -it --name busybox busybox
- Docker会检查本地是否存在busybox镜像
- 使用busybox镜像创建并启动一个容器
- 分配文件系统,并在镜像只读层外创建一个读写层
- 从Docker IP池中分配一个IP给容器
- 执行用户的启动命令运行镜像
对容器来说,杀死容器中的主进程,则容器也会被杀死。
问题:
==为什么容器的文件系统要设计成写时复制,而不是每一个容器都单独拷贝一份镜像文件?==
容器命令
在Docker中,使用run来生成一个一个的容器实例
新建+启动容器
docker run -it -name tfsc –gpus all -p 8089:22 -shm-size 32g
docker run [OPTIONS] IMAGE [COMMAND][ARG...]:
[OPTIONS]说明:
- –name=”容器名字”
- -d: 后台运行容器并返回容器ID,也即启动守护式容器
- -i:以交互式模是与你虚拟狗让其,通常与-t同时使用
- -t:为容器重新分配一个伪输入终端,通常与-i同时使用
也即启动交互式容器(前台有伪终端,等待交互) - -P -p 端口分配

==docker run -it ubuntu /bin/bash== : 启动一个ubuntu镜像实例化的容器
docker run -it --name=shenchen ubuntu bash: 命名容器
docker run -it --name="sc" --gpus all --shm-size 32g registry.baidubce.com/paddlepaddle/paddle:2.3.2-gpu-cuda11.2-cudnn8 /bin/bash
镜像名称:TAG 放在最后,/bin/bash之前
重命名容器
docker rename 旧容器名 新容器名
列出当前所有运行的容器
docker ps [OPTIONS] : 列出当前所有正在运行的容器实例
[OPTIONS]:
- -a:列出当前所有正在运行的容器,和运行过的容器
- -l:显示最近创建的容器
- -n:显示最近n个创建的容器
- -q:静默模式,只显示容器编号
退出容器
exit: run进去,exit退出,容器停止
ctrl+p+q: 容器不停止
启动已经停止运行的容器
docker start 容器ID或者容器名字
重启容器
docker restart 容器ID或者容器名
停止容器
docker stop 容器ID或容器名 [-t|--time[=10]]
- 该命令首先会向运行中的容器发送SIGTERM(软件终止信号)信号。如果容器内1号接受并能够处理SIGTERM,则等待1号进程处理完毕并退出。
- 如果等待一段时间后,容器仍然没有退出,则会发送SIGKILL(杀死进程)强制中止容器。
强制停止容器
docker kill 容器ID或容器名
删除已停止的容器
docker rm 容器ID
==注意:rmi删的是镜像image,rm删的是容器container==
rm -f 强制删除
一次性删除多个容器:
| xargs 管道参数:docker ps -a -q的命令结果可以直接作为docker rm 的输入参数
如何重新进入活动状态下的容器?
启动守护式容器
docker run -d 镜像 : 守护式容器
==but== docker容器后台运行,就必须有一个前台进程。最佳解决方案:将你要运行的程序以前台进程的形式运行。
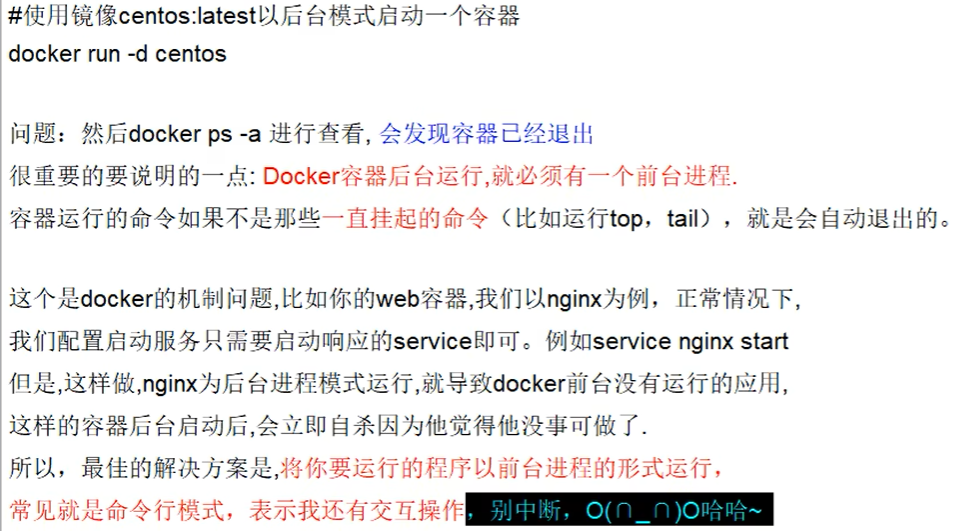
使用 docker run -d redis
docker ps redis不会退出,而是会正常显示,因为redis有服务器功能,ubuntu直接退出,因为ubuntu只是操作系统
查看容器日志
docker logs 容器号/容器名
查看容器内的运行进程
docker top 容器号
查看容器内部细节
docker inspect 容器ID
==进入正在运行的容器并以命令行交互==
docker exec -it 容器ID /bin/bash
docker attach 容器ID :注意:同时使用docker attach命令同时在多个终端运行时,所有的终端窗口将同步显
示相同内容,当某个命令行窗口的命令阻塞时,其它命令行窗口同样也无法操作。
esenter
区别:
- attach 直接进入容器启动命令的终端,不会启动新的进程,用exit退出,会导致容器的停止
- exec是在容器中打开新的终端,并且可以启动新的进程,用exit退出,不会导致容器终止。每个窗口都是独立且相互不干扰的。
从容器内拷贝文件到主机上
容器——> 主机
docker cp 容器ID:容器内路径 目的主机路径
导入和导出容器
export导出容器的内容留作一个tar归档文件[对应import命令]
import从tar包中的内容创建一个新的文件系统再导入为镜像[对应export]
docker export 容器ID > 文件名.tar 默认导出到当前目录下面,相当于把整个容器打成了一个tar包,备份了整个容器
cat 文件名.tar | docker import -镜像用户/镜像名:镜像版本号
docker import [OPTIONS] file|URL [REPOSITORY[:TAG]]
执行完docker import之后,会变成本地镜像,最后使用docker run启动该镜像
例子
docker import busybox.tar busybox:test
提交容器为镜像
docker commit dd53ea4c2f2b ubuntu:ssh
镜像
镜像是分层的
UnionFS联合文件系统
Union文件系统〈UnionFS)是一种分层、轻量级并且高性能的文件系统,它支持对文件系统的修改作为一次提交来一层层的叠加,同时可以将不同目录挂载到同一个虚拟文件系统下(unite several directories into a single virtual filesystem)。Union文件系统是Docker镜像的基础。镜像可以通过分层来进行继承,基于基础镜像(没有父镜像),可以制作各种具体的应用镜像。
docker镜像加载原理
docker的镜像实际上由一层一层的文件系统组成,这种层级的文件系统UnionFS。
bootfs(boot file system)主要包含bootioader和kernel, bootoader主要是引导加载kernel, Linux刚启动时会加载bootfs文件系统,在Docker镜像的最底层是引导文件系统bootfs。这一层与我们典型的LinuxUnix系统是一样的,包含boot加载器和内核。当boot加载完成之后整个内核就都在内存中了,此时内存的使用权已由bootfs转交给内核,此时系统也会卸载bootfs。rootfs (root fle system),在bootfs之上。包含的就是典型Linux系统中的/dev, /proc, /bin, letc等标准目录和文件。rootfs就是各种不同的操作系统发行版,比如Ubuntu,Centos等等。
镜像的实现原理
Docker镜像是由一系列镜像层(layer)组成的,每一层代表了镜像构建过程中的一次提交。


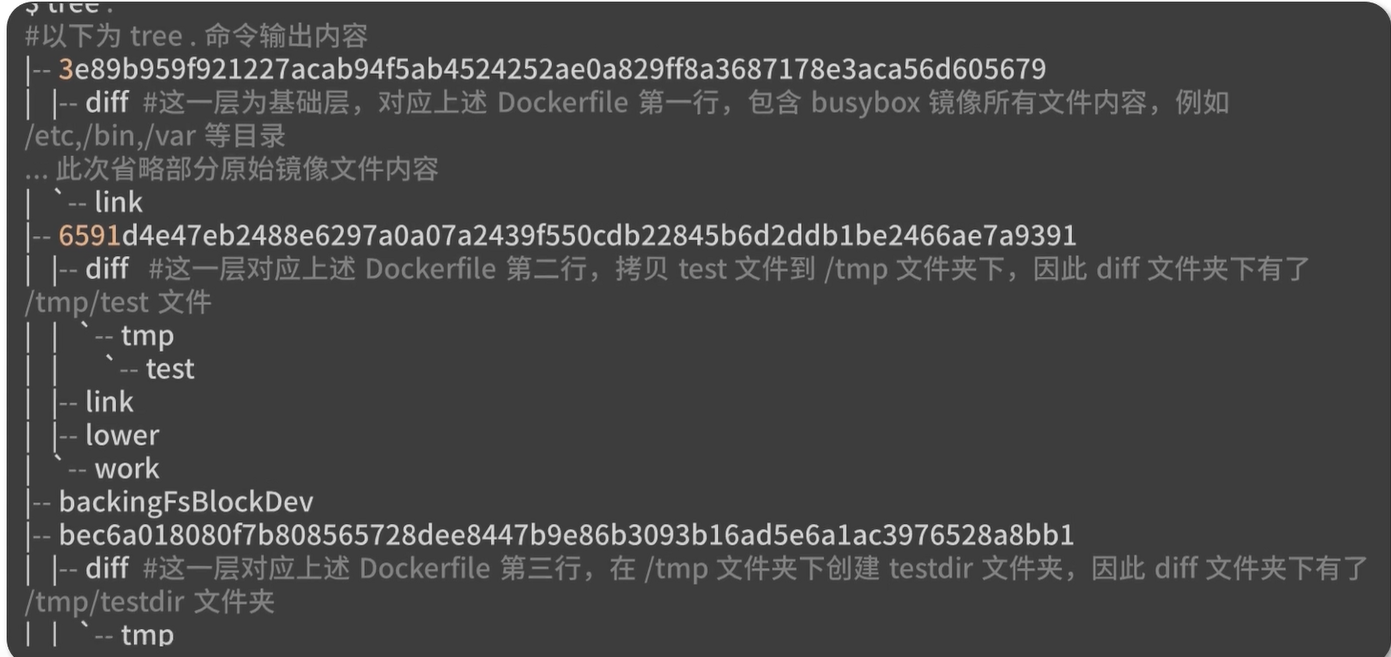

Dockerfile的每一行命令都生成了一个镜像层,每一层的diff文件夹下只存放了增量数据。分层的结构使得docker镜像非常轻量,每一层根据镜像的内容都有一个唯一的ID。
==当不同的镜像之间有相同的镜像层时,便可以实现不同的镜像层之间共享镜像层的效果==
总结:
Docker镜像是静态的分层管理的文件组合,镜像底层的实现依赖于联合文件系统UnionFS。
镜像是由一系列的镜像层(layer)组成,每一层代表了镜像构建过程中的一次提交,当需要修改镜像内的某个文件时,只需要在当前镜像层的基础上新建一个镜像层,并且只存放修改过的文件内容。
构建镜像
docker commit
从运行中的容器提交为镜像
docker commit: 提交容器副本使之成为一个新的镜像
docker commit -m=: “提交的描述信息” -a="作者" 容器ID 要创建的目标镜像名:[标签名]
touch test.txt && echo "I love Docker">test.txt
docker build
从Dockerfile构建镜像
docker save
docker save -o hosttorch.tar 7e420a6c07e4
将某个镜像打包成tar包,并使用xfpt传输到其他服务器使用。
docker load
docker port
使用docker port 容器号/容器名 来查看容器端口的绑定情况
docker pull
使用该命令往dockerhub上传镜像时,必须保证镜像的名称和dockerhub中创建的仓库名称相同,否则无法上传,出现 denied: requested access to the resource is denied 错误
若不相同,采用docker tag命令更改镜像名称
docker tag
docker tag 老名称 新名称
新名称要加上用户名dutsc/
重命名之后,只是改了一个名称而已,新镜像的image iD与原来的镜像是一样的。
终止GPU中运行的程序
- 使用nvidia-smi查看运行的进程号
- 使用kill -9 PID 就可以杀死进程了
Dockerfile
构建docker镜像的一个配置文件,说明了docker镜像应该如何构建
Dockerfile包含了用户所有的构建命令
使用时,必须在文件夹下创建一个文件,名称叫==Dockerfile== ,而且只能叫这个名字,不能叫别的名字。
Dockerfile的优点
- 易与版本化管理,纯文本文件
- 过程可追溯
- 屏蔽构建环境异构
Dockerfile的特点
- Dockerfile的每一行命令都会生成一个独立的镜像层,并且拥有唯一的ID
- Dockerfile的命令是完全透明的,通过查看Dockerfile的内容,可以知道镜像是如何一步步构建的。
- Dockerfile是纯文本的,方便跟随代码一起放在代码仓库并作版本管理。
Docker常用指令

一个Dockerfile的实例
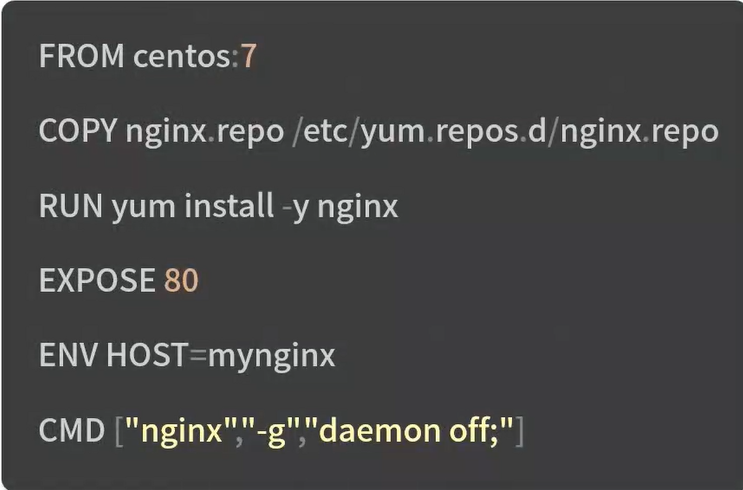
构建镜像的命令 docker build
下面介绍最常用的五个指令
from
指定当前镜像是基于哪个镜像
workdir
指定进入之后的工作目录
copy
把当前服务器上的某个文件或者目录复制到容器中
run
在起来的容器中运行命令
cmd
可以写/bin/bash

expose
暴露的端口是什么
volume
指定被映射的文件夹
在docker run的时候可以指定服务器中映射的文件夹

env
直接指定当前容器的环境变量
也可以在docker run中通过-e指定环境变量
1 | |
注意与arg的区别:env是建立系统的环境变量,从构建(build)到运行都有效;但是arg只在构建时有效,运行时无效。
arg
1 | |
可以在run容器时使用--build-arg B=11 来修改B的值,
label
用来指定元数据信息
1 | |
只是作为镜像的一个标识,并没有实质性的作用,在使用docker inspect 镜像名 时标识镜像,没有实质性的作用。
onbuild
onbuild是指当前镜像构建的时候不会执行,基于当前镜像的镜像构建的时候才会执行。
onbuild后面加的参数可以是dockerfile中的其他任意参数
1 | |
stopsignal
当前构建的容器用什么样的信号能够使其停止。一般不常用
healthcheck
用来检查容器健康状态的一些配置,很少用到,不讲
shell
指定当前构建的镜像使用什么shell,一般linux默认/bin/sh win使用cmd
Dockerfile书写原则
单一职责:由于容器的本质是进程,一个容器代表一个进程,因此不同的功能应用应该尽量拆分成不同的容器,每个容器只负责单一业务进程。
提供注释信息
保持容器最小化:应该避免安装无用的软件包
合理选择基础镜像:容器的核心是应用,只要基础镜像能够满足应用的环境即可。例如:一个java类型的应用,运行时只需要JRE,并不需要JDK,因此容器只安装JRE即可。
使用.dockerignore文件忽略一些不需要构建的文件
尽量使用构建缓存

因此,基于docker构建时的缓存特性,我们可以把不轻易改变的指令放在Dockerfile前面,而可能经常改变的指令放在Dockerfile末尾,
正确设置时区。

使用国内软件园加快镜像构建速度
最小化镜像层数

Dockerfile指令书写建议
RUN:RUN指令在执行时将会生成一个新的镜像层并且执行RUN指令后面的内容
当RUN指令后面跟的内容比较复杂时,建议使用反斜杠\结尾并换行
RUN指令后面的内容尽量按照字母顺序排序,提高可读性
一个示例
1
2
3
4
5FROM centos:7
RUN yum install -y automake \
curl \
python \
vim
CMD\ENTRYPOINT
相同点
两者后面都跟JSON参数
1
CMD/ENTRYPOINT ["command","param"]跟shell指令 shell模式
1
CMD/ENTRYPOINT command param
不同点
- Dockerfile中如果使用了ENTRYPOINT指令,启动Docker容器时需要使用–entrypoint 参数才能覆盖Dockerfile中的ENTRYPOINT指令,而使用CMD设置的命令则可以被docker run后面的参数直接覆盖
- ENTRYPOINT指令可以结合CMD指令使用,也可以单独使用,而CMD指令只能单独使用
什么时候使用CMD,什么时候使用ENTRYPOINT呢?
希望镜像足够灵活,推荐使用CMD指令;如果镜像只执行单一的程序,并且不希望用户在执行docker run时覆盖默认程序,建议使用ENTRYPOINT
无论使用CMD还是ENTRYPOINT,都尽量使用exec
ADD\COPY,功能类似,都是从外部往容器内添加文件
COPY指令只支持基本的文件和文件夹拷贝功能
ADD支持更多文件来源类型,比如自动提取tar包,并且支持源文件为URL格式。
日常使用中,应该使用哪个指令添加文件呢?
推荐使用COPY指令,因为它更加透明,更容易使用缓存,有效减少容器体积
希望使用ADD指令添加URL文件时,应避免使用
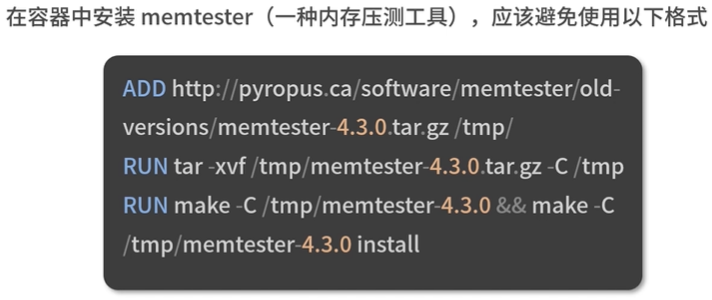
下面是推荐写法

推荐使用WORKDIR指定容器的工作路径,因为这样能够使容器的工作过程更加清晰明了。应该尽量避免使用
RUN cd /work/path && do some work这样的指令
问题:当需要编写编译型语言(Go,Java)的Dockerfile时,如何分离编译环境和运行环境使得镜像体积尽可能小呢?
Docker安全
基于内核的弱隔离系统如何保障安全性?
Docker是基于Linux内核的Namespace技术实现资源隔离的,所有的容器都共享宿主机的内核。容器比虚拟机的安全性弱多了。
下图展示容器与虚拟机的区别:
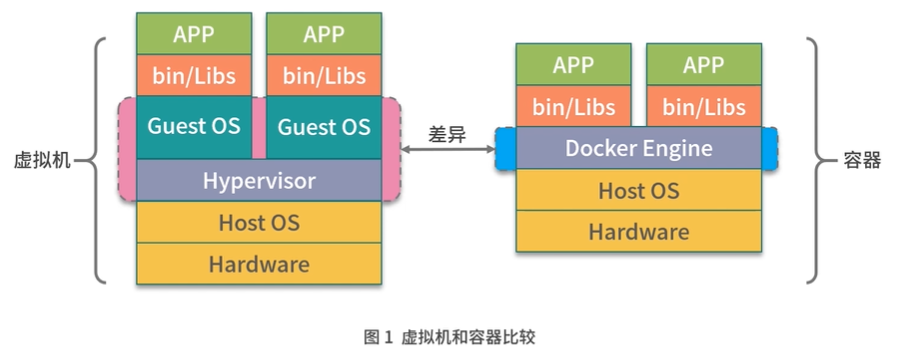
- 虚拟机:通过管理系统模拟出CPU,内存,网络等硬件,然后在这些模拟的硬件上创建客户内核和操作系统。好处:虚拟机有自己的内核和操作系统,并且硬件都是通过虚拟机管理系统模拟出来的,用户程序无法直接使用到主机的操作系统和硬件资源。
- 容器:通过Linux的namespace技术实现了进程,设备,网络以及文件系统的隔离,然后再通过cgroup对CPU,内存等资源进行限制,最终实现了容器之间相互不受影响。因为容器的隔离性仅仅依靠内核提供,因此,容器的隔离性也远弱于虚拟机。
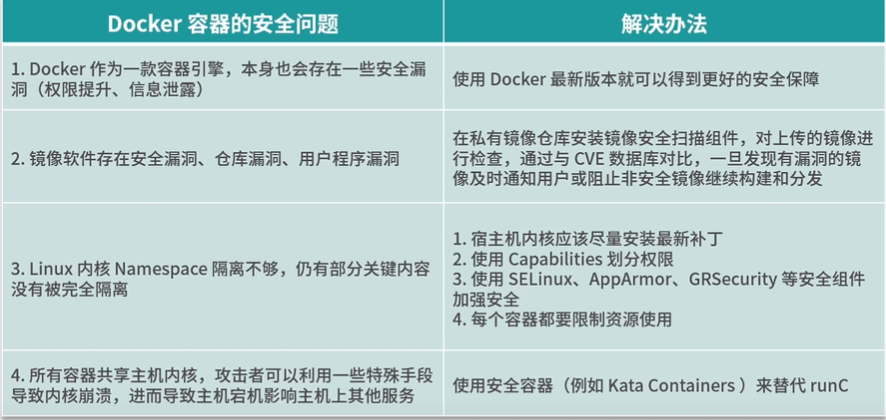
Docker存在的安全问题
https://docs.docker.com/engine/security/non-events/
Docker是一种容器引擎,也会存在一些容器漏洞;比如权限提升,信息泄露等等。
镜像安全
- 镜像软件存在漏洞
- 仓库漏洞
- 用户程序漏洞
尽管目前Namespace已经提供了非常多的资源隔离类型,但是仍有部分关键内容没有被完全隔离,其中包括一些系统的关键性目录(如/sys,/proc等)
由于同一宿主机上的所有容器共享主机内核,攻击者可以使用一些手段导致内核崩溃,进而导致主机宕机,影响主机上的其他服务。
保障镜像安全
- 在私有仓库中 安装镜像安全扫描组件,对上传的镜像进行检查
- 拉去镜像是从受信任的仓库中拉取,并且与镜像仓库通信一定要使用htps协议
UserNamespace
主要是用来容器内用户和主机的用户隔离的
Docker1.10版本开始,使用UserNamespace做用户隔离,实现了容器中的root用户映射到主机上的非root用户
加强内核安全和管理
宿主机及时升级内核漏洞
使用Capabilities划分权限
- 在虚拟机内可以赋予用户所有的权限,例如设置cron定时任务,操作内核模块,配置网络等权限
- 容器需要针对每一项Capabilities更细粒度控制权限
- 大多数情况下,容器不需要主机的root权限,Docker默认情况下也不开启额外特权
- 在执行docker run命令启动容器时,如非特殊可控情况,–privileged参数不允许设置为true
- 其他特殊权限可以使用–cap-add参数,根据使用场景适当添加相应的权限
使用安全加固组件
以下三种组件可以控制容器内部对系统内核的访问
- SELinux:是Linux的一个内核安全模块,提供了安全访问的策略机制,通过设置SELinux策略可以实现某些进程允许访问某些文件。
- AppArmor:是Linux的内核安全模块,AppArmor可以控制到用户程序的访问权限
- GRSecurity:是一个对内核的安全扩展,可通过智能访问控制,提供内存破坏防御,文件系统增强等多种防御形式。
资源限制
docker run命令时资源限制的参数
--cpu:限制cpu配额-m:限制内存配额--pids-limit:限制容器PID个数
启动一个1核2G的容器,并且限制在容器内最多只能创建1000个PID
1
docker run --cpu 1 -m 2048m --pids-limit=1000 busybox sh这样即便容器的程序有漏洞,也不会导致主机的资源被耗尽,最大限度降低安全风险
使用安全容器
兼顾轻便 与 安全
安全容器中的每个容器都运行在一个单独的微型虚拟机中,拥有独立的操作系统和内核,并且有虚拟化层的安全隔离
Kata Container只有一个精简版的Guest Kernel运行着容器本身的应用,并且通过减少不必要的内存,尽量共享可以共享的内存来进一步减少内存的开销。
Kata Container实现了OCI规范,可以直接使用Docker的镜像启动Kata容器具有开销更小、秒级启动、安全隔离等许多优点。
总结
==问题==
除了Kata container之外,是否还知道其他的安全容器解决方案?
容器监控
容器监控的解决方案
- docker stats命令 缺点:只能获取本机数据,无法获取历史化监控数据,没有可视化展示面板
- 开源解决方案:sysdig,cAdvisor,Prometheus等
cAdvisor
采集机器上所有运行的容器信息,提供基础的查询界面和HTTP接口
启动cAdvisor
1 | |
监控原理
Docker是基于Namespace,Cgroups和联合文件系统实现的。
Cgroups不仅可以用于容器资源的的限制,还可以提供容器的资源使用率
Cgroups的工作目录/sys/fs/cgroup 下包含了Cgroups的所有内容 ==容器监控的数据来自cgroups==
==容器的监控原理其实就是定时读取Linux主机上的相关文件并展示给用户==
监控memory
/sys/fs/cgroup/memory/docker/容器ID目录下存在某个容器的内存监控文件- 比如
memory.limit_in_bytes文件 存放了该容器限制的内存大小 单位bytes
监控网络
查看容器的PID 使用docker inspect命令 容器的PID为容器在主机上运行的进程ID
docker inspect busybox |grep Pid
/proc/容器PID/net/dev文件记录了容器内每一个网卡的流量接收和发送情况,以及错误数,丢包数等信息。可见容器的监控数据都是定时从这里读取并展示的。
==在大规模容器集群当中,cAdvisor有什么明显的不足吗==
Namespace
Namespace 是 Linux内核的一项功能,该功能对内核资源进行分区,以使一组进程看到一组资源,而另一组进程看到另一组资源。Namespace的工作方式通过为一组资源和进程设置相同的Namespace而起作用,但是这些Namespace 引用了不同的资源。资源可能存在于多个Namespace中。这些资源可以是进程ID、主机名、用户ID、文件名、与网络访问相关的名称和进程间通信。
八种namespace
| Namespace 名称 | 作用 | Linux内核版本 |
|---|---|---|
| Mount(mnt) | 隔离挂载点:隔离不同的进程或进程组看到的挂载点。实现容器内只能看到自己的挂载信息,在容器内的挂载操作不会影响主机的挂载目录 | 2.4.19 |
| Process ID(pid) | 隔离进程ID | 2.6.24 |
| Network(net) | 隔离网络设备,端口号等 | 2.6.29 |
| Interprocess Communication(ipc) | 隔离System V IPC和POSIX message queues:PID Namespace和IPC Namespace一起使用可以实现同一IPC Namespace内的进程彼此可以通信,不同IPC Namespace的进程却不能通信 | 2.6.19 |
| UTS Namespace(uts) | 隔离主机名和域名: 允许每个UTS namespace拥有一个独立的主机名 | 2.6.19 |
| User Namespace(user) | 隔离用户和用户组 | 3.8 |
| Control group(cgroup) Namespace | 隔离Cgroups根目录 | 4.6 |
| Time Namespace | 隔离系统时间 | 5.6 |
docker只实现了前六种,后两种没实现
unshare
unshare: 是util-linux工具包中的一个工具,可以实现创建并访问不同类型的Namespace
ls -l /proc/self/ns 查看当前进程的Namespace信息
unshare的选项
1 | |
mount namespace
创建一个bash进程并新建一个mount namespace
sudo unshare --mount --fork /bin/bash
使用unshare命令可以新建Mount Namespace,并且在新建的Mount Namespace内mount是和外部完全隔离的。
它可以用来隔离不同的进程或进程组看到的挂载点。通俗地说,就是可以实现在不同的进程中看到不同的挂载目录。
执行完上述unshare命令后,这时我们已经在主机上创建了一个新的 Mount Namespace,并且当前命令行窗口加入了新创建的 Mount Namespace。下面我通过一个例子来验证下,在独立的 Mount Namespace 内创建挂载目录是不影响主机的挂载目录的。
首先在 /tmp 目录下创建一个目录。
1 | |
创建好目录后使用 mount 命令挂载一个 tmpfs 类型的目录。命令如下:
1 | |
然后使用 df 命令查看一下已经挂载的目录信息:
1 | |
1 | |
可以看到 /tmp/tmpfs 目录已经被正确挂载。为了验证主机上并没有挂载此目录,我们新打开一个命令行窗口,同样执行 df 命令查看主机的挂载信息:
1 | |
通过上面输出可以看到主机上并没有挂载 /tmp/tmpfs,可见我们独立的 Mount Namespace 中执行 mount 操作并不会影响主机。
为了进一步验证我们的想法,我们继续在当前命令行窗口查看一下当前进程的 Namespace 信息,命令如下:
1 | |
然后新打开一个命令行窗口,使用相同的命令查看一下主机上的 Namespace 信息:
1 | |
通过对比两次命令的输出结果,我们可以看到,除了 Mount Namespace 的 ID 值不一样外,其他Namespace 的 ID 值均一致。
通过以上结果我们可以得出结论,使用 unshare 命令可以新建 Mount Namespace,并且在新建的 Mount Namespace 内 mount 是和外部完全隔离的。
PID namespace
通过PID namespace实现隔离进程,在不同的PID namespace内,进程可以拥有相同的PID号。
创建一个bash进程,并新建一个PID namespace
sudo unshare --pid --fork --mount-proc /bin/bash
ps aux 查看当前进程的所有信息
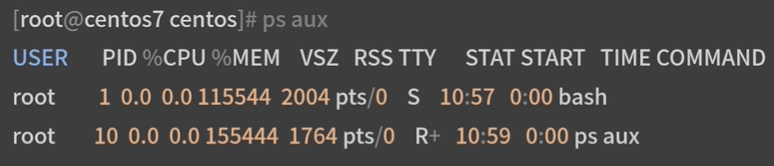
通过上述命令输出结果可以看到当前 Namespace 下 bash 为 1 号进程,而且我们也看不到主机上的其他进程信息。
UTS namespace
hostname 查看主机名
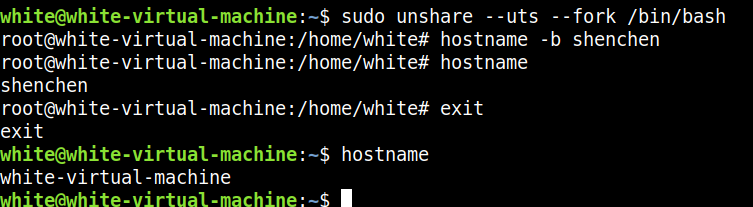
hostname -b 临时修改主机名
容器场景中的UTS namespace
容器场景下,由于实现了uts_namespace,获取当前utsname时,都是获取当前上下文进程的所在的uts命名空间中的utsname来实现的,如下:

每一个进程都有一个属于自己的uts命名空间。多个进程可共享这个命名空间 。
创建容器时,通过CLONE_UTSNS来指定一个新的命名空间。待容器中的init进程创建子进程时,子进程复制其父进程的uts命名空间。这样做到了再一个容器中的所有进程共享一个uts命名空间,从而其相应的utsname信息也是共享一份的。
IPC namespace
在单独的IPC namespace中创建的系统通信队列,在主机中无法看到
sudo unshare --ipc --fork /bin/bash
ipcs -q 查看系统间通信队列列表
ipcmk -Q 创建系统间通信队列
User namespace
使用User Namespace可以实现进程在容器内拥有root权限,而在主机上却只是普通用户
User Namespace 主要是用来隔离用户和用户组的。一个比较典型的应用场景就是在主机上以非 root 用户运行的进程可以在一个单独的 User Namespace 中映射成 root 用户。使用 User Namespace 可以实现进程在容器内拥有 root 权限,而在主机上却只是普通用户。
User Namesapce 的创建是可以不使用 root 权限的。下面我们以普通用户的身份创建一个 User Namespace,命令如下:
1 | |
创建一个user namespace
CentOS7 默认允许创建的 User Namespace 为 0,如果执行上述命令失败( unshare 命令返回的错误为 unshare: unshare failed: Invalid argument ),需要使用以下命令修改系统允许创建的 User Namespace 数量,命令为:echo 65535 > /proc/sys/user/max_user_namespaces,然后再次尝试创建 User Namespace。
id 查看当前的用户信息
在隔离的user namespace中,并不能获得主机的root权限
Net namespace
Net Namespace 可以让每个进程拥有自己独立的IP地址,端口和网卡信息例如主机IP地址为172.16.4.1,容器内可以设置独立的IP地址为192.168.1.1。
同样用实例验证,我们首先使用 ip a 命令查看一下主机上的网络信息:
1 | |
然后我们使用以下命令创建一个 Net Namespace:
1 | |
同样的我们使用 ip a 命令查看一下网络信息:
1 | |
可以看到,宿主机上有 lo、eth0、docker0 等网络设备,而我们新建的 Net Namespace 内则与主机上的网络设备不同。
总结
Linux内核从2002年2.4.19版本开始加入了Mount Namespace内核3.8版本加入了User Namespace为容器提供了足够的支持功能。
当Docker新建一个容器时,会创建这六种Namespace,然后将容器中的进程加入这些Namespace之中
没有namespace 就没有docker容器
Namespace是 Linux内核的一个特性,可以实现在同一主机系统中对进程ID、主机名、用户ID、文件名、网络和进程间通信等资源的隔离
Cgroups
cgroups机制实现资源限制
虽然有了namespace,使得不同容器之间看不到相互的资源,但是容器内的进程依然可以使用主机的CPU 内存等资源 。如何限制一个容器资源的使用???使用Cgroups
cgroups(全称: control groups),是Linux内核的一个功能,可以实现限制进程或者进程组的资源(如CPU、内存、磁盘IO等)。
核心功能
- 资源限制:限制资源使用量
- 优先级控制:不同的组可以有不同的资源使用优先级
- 审计:计算控制组的资源使用情况
- 控制:控制进程的挂起或恢复
核心概念
子系统 subsystem:是一个内核的组件,一个子系统代表一类资源调度控制器
- 内存子系统可以限制内存的使用量
- cpu子系统可以限制cpu的使用时间
是真正实现某类资源限制的基础
控制组 cgroups :表示一组进程和一组带有参数的子系统的关联关系
- 一个进程使用cpu子系统来限制cpu的使用时间,则这个进程和cpu子系统的关联关系成为控制组
层级树 hierarchy :是由一系列控制组按照树状结构排列组成的,子控制组默认拥有父控制组的属性。
- 比如系统中定义了控制组c1,限制cpu可以使用1核;另外一个控制组c2,想实现限制cpu使用1核,同时实现内存使用2G,那么c2就可以直接继承c1,无需重复定义CPU资源限制。
sudo mount -t cgroups 查看挂载的cgroups子系统信息
以cpu子系统为例,查看限制cpu使用的情况
查看meory内存使用情况
在memory子系统下创建cgroup测试文件夹
/sys/fs/cgroup/memory/mydocker里面会自动创建一些内存限制使用文件对内存限制使用为1G
echo 1073741824>memory.limit_in_bytes创建进程 加入Cgroup
echo $$>tasks把当前shell进程ID写入tasks文件内执行内存测试工具 memtester 1500M 1
当tasks中的进程内存使用超过1G时,会被cgroups杀死
docker是如何使用cgroups的
docker创建容器时,docker会根据启动容器的参数,在对应的cgroups子系统下,创建以容器ID为名称的目录,然后根据容器启动时设置的资源限制参数,修改对应的cgroups子系统资源限制文件,从而达到资源限制的效果。
==注意==
cgroups虽然能实现资源的限制,但不保证资源的使用
/sys/fs/cgroup目录下各文件夹含义
- blkio 对块设备的 IO 进行限制
- cpu 限制 CPU 时间片的分配,与 cpuacct 挂载在同一目录
- cpuacct 生成 cgroup 中的任务占用 CPU 资源的报告,与 cpu 挂载在同一目录
- cpuset 给 cgroup 中的任务分配独立的 CPU(多处理器系统) 和内存节点
- devices 允许或禁止 cgroup 中的任务访问设备
- freezer 暂停/恢复 cgroup 中的任务
- hugetlb 限制使用的内存页数量
- memory 对 cgroup 中的任务的可用内存进行限制,并自动生成资源占用报告
- net_cls 使用等级识别符(classid)标记网络数据包,这让 Linux 流量控制器(tc 指令)可以识别来自特定
- cgroup 任务的数据包,并进行网络限制
- net_prio 允许基于 cgroup 设置网络流量(netowork traffic)的优先级
- perf_event 允许使用 perf 工具来监控 cgroup
- pids 限制任务的数量
- rdma 限制进程对rdma和ib资源的使用。rdma作为host-offload、host-bypass技术,使低延迟、高带宽的直接内存到内存的数据通信成为可能。ib为新一代网络协议
- systemd systemd 提供了 cgroups 的使用和管理接口,在系统的开机阶段,systemd 会把支持的 controllers (subsystem 子系统)挂载到默认的 /sys/fs/cgroup/ 目录下面
docker组件剖析
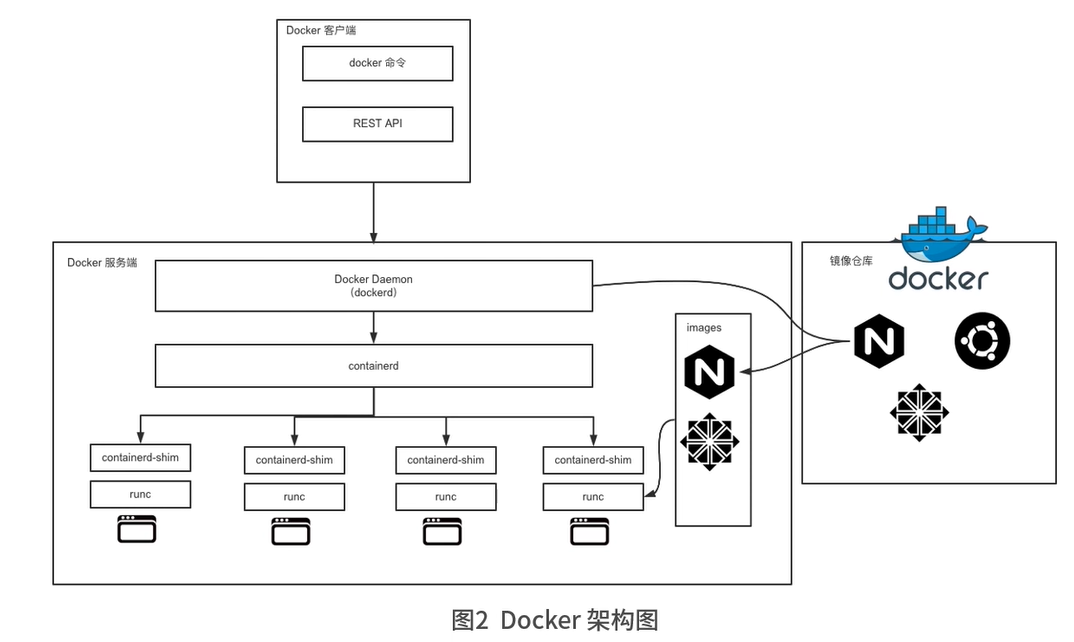
客户端与服务端默认通信方式:Unix套接字
- docker相关的组件
- docker:二进制文件,负责发送docker操作请求
- dockerd:docker服务端的后台常驻进程,用来接收客户端发送的请求
- docker-init:docker run时采用–init参数启动,回收docker内的进程,在业务进程没有进程回收功能时十分有用
- docker-proxy:做端口映射,底层依赖于iptables实现
- containerd相关的组件
- containerd:负责管理容器的生命周期
- containerd-shim:containerd-shim的意思是垫片,主要作用是将containerd和真正的容器进程解耦。使用containerd-shim 作为容器进程的父进程,从而实现重启containerd不影响已经启动的容器进程。
- ctr:ctr实际上是containerd-ctr,是containerd的客户端,主要用来开发和调试在没有dockerd的环境中,ctr可以直接向containerd守护进程发送操作容器的请求。
- 容器运行时组件runc
总结:
| 组件分类 | 组件名称 | 作用剖析 |
|---|---|---|
| docker相关组件 | docker | Docker的客户端,负责发送Docker操作请求 |
| docker相关组件 | dockerd | Docker服务端入口,负责接收客户端请求并返回请求结果 |
| docker相关组件 | docker-init | 当业务主进程没有进程回收能力时,docker-int可以作为容器的1号进程,负责管理容器内子进程 |
| docker相关组件 | docker-proxy | 用来做Docker的网络实现,通过设置iptables规则使得访问到主机的流量可以被顺利转发到容器中 |
| containerd相关组件 | containerd | 负责管理容器的生命周期,通过接收dockerd的请求,执行启动或者销毁容器操作 |
| containerd相关组件 | containerd-shim | 将containerd和真正的容器进程解耦,使用containerd-shim 作为容器进程的父进程,可以实现重启containerd不影响已经启动的容器进程 |
| containerd相关组件 | ctr | containerd的客户端,可以直接向containerd发送容器操作请求,主要用来开发和调试 |
| 容器运行时组件 | runc | 通过调用Namespace、cgroups等系统接口,实现容器的创建和销毁 |
docker网络
CNM(container network model) 是docker发布的容器网络标准,只要满足CNM接口的网络方案都可以接入到docker容器网络
CNM
- 沙箱
- 接入点
- 网络
Libnetwork
是CNM的官方实现,是启动容器时为docker容器提供网络接入功能的插件
route -n 查看路由信息
Libnetwork工作流程
- Docker通过调用libnetwork.New函数来创建NetworkController实例
- 通过调用NewNetwork函数创建指定名称和类型的Network
- 通过调用CreateEndpoint来创建接入点(Endpoint)
- 调用NewSandbos来创建容器沙箱,主要是初始化Namespace相关的资源
- 调用Endpoint的join函数将沙箱和网络接入点关联起来
LIbnetwork常见的网络模式
| Libnetwork常见的网络模式 | 作用 | 业务场景 |
|---|---|---|
| null空网络模式 | 不提供任何容器网络 | 处理一些保密数据,出于安全考虑,需要一个隔离的网络环境执行一些纯计算任务 |
| bridge桥接模式 | 使得容器和容器之间网络可以互通 | 容器需要实现网络通信或者提供网络服务 |
| host主机网络模式 | 让容器内的程序可以使用到主机的网络 | 容器需要控制主机网络或者用主机网络提供服务 |
| container网络模式 | 将两个容器放到同一网络空间中,可以直接通过localhost本地访问 | 两个容器之间需要直接通过localhost通信,一般用于网络接管或代理场景 |
数据存储:卷(volume)
前面我已经介绍过,容器技术使用了 rootfs 机制和 Mount Namespace,构建出了一个同宿主机完全隔离开的文件系统环境。这时候,我们就需要考虑这样两个问题:
容器里进程新建的文件,怎么才能让宿主机获取到?
宿主机上的文件和目录,怎么才能让容器里的进程访问到?
这正是 Docker Volume 要解决的问题:Volume 机制,允许你将宿主机上指定的目录或者文件,挂载到容器里面进行读取和修改操作。
在 Docker 项目里,它支持两种 Volume 声明方式,可以把宿主机目录挂载进容器的 /test 目录当中:
1 | |
而这两种声明方式的本质,实际上是相同的:都是把一个宿主机的目录挂载进了容器的 /test 目录。
只不过,在第一种情况下,由于你并没有显示声明宿主机目录,那么 Docker 就会默认在宿主机上创建一个临时目录 /var/lib/docker/volumes/[VOLUME_ID]/_data,然后把它挂载到容器的 /test 目录上。而在第二种情况下,Docker 就直接把宿主机的 /home 目录挂载到容器的 /test 目录上。
绑定挂载
那么,Docker 又是如何做到把一个宿主机上的目录或者文件,挂载到容器里面去呢?难道又是 Mount Namespace 的黑科技吗?
实际上,并不需要这么麻烦。
当容器进程被创建之后,尽管开启了 Mount Namespace,但是在它执行 chroot(或者 pivot_root)之前,容器进程一直可以看到宿主机上的整个文件系统。
而宿主机上的文件系统,也自然包括了我们要使用的容器镜像。这个镜像的各个层,保存在 /var/lib/docker/aufs/diff 目录下,在容器进程启动后,它们会被联合挂载在 /var/lib/docker/aufs/mnt/ 目录中,这样容器所需的 rootfs 就准备好了。
所以,我们只需要在 rootfs 准备好之后,在执行 chroot 之前,把 Volume 指定的宿主机目录(比如/home目录),挂载到指定的容器目录(比如 /test 目录)在宿主机上对应的目录(即 /var/lib/docker/aufs/mnt/[可读写层 ID]/test)上,这个 Volume 的挂载工作就完成了。
更重要的是,由于执行这个挂载操作时,“容器进程”已经创建了,也就意味着此时 Mount Namespace 已经开启了。所以,这个挂载事件只在这个容器里可见。你在宿主机上,是看不见容器内部的这个挂载点的。这就保证了容器的隔离性不会被 Volume 打破。
注意:这里提到的 “ 容器进程 “,是 Docker 创建的一个容器初始化进程 (dockerinit),而不是应用进程 (ENTRYPOINT + CMD)。dockerinit 会负责完成根目录的准备、挂载设备和目录、配置 hostname 等一系列需要在容器内进行的初始化操作。最后,它通过
execv()系统调用,让应用进程取代自己,成为容器里的 PID=1 的进程。
而这里要使用到的挂载技术,就是 Linux 的绑定挂载(bind mount)机制。它的主要作用就是,允许你将一个目录或者文件,而不是整个设备,挂载到一个指定的目录上。并且,这时你在该挂载点上进行的任何操作,只是发生在被挂载的目录或者文件上,而原挂载点的内容则会被隐藏起来且不受影响。
其实,如果你了解 Linux 内核的话,就会明白,绑定挂载实际上是一个 inode 替换的过程。在 Linux 操作系统中,inode 可以理解为存放文件内容的“对象”,而 dentry,也叫目录项,就是访问这个 inode 所使用的“指针”。

正如上图所示,mount --bind /home /test,会将 /home 挂载到 /test 上。其实相当于将/test的 dentry,重定向到了 /home 的 inode。这样当我们修改 /test 目录时,实际修改的是/home目录的 inode。这也就是为何,一旦执行 umount 命令,/test 目录原先的内容就会恢复:因为修改真正发生在的,是 /home 目录里。
所以,在一个正确的时机,进行一次绑定挂载,Docker 就可以成功地将一个宿主机上的目录或文件,不动声色地挂载到容器中。
这样,进程在容器里对这个/test目录进行的所有操作,都实际发生在宿主机的对应目录(比如,/home,或者 /var/lib/docker/volumes/[VOLUME_ID]/_data)里,而不会影响容器镜像的内容。
那么,这个 /test 目录里的内容,既然挂载在容器 rootfs 的可读写层,它会不会被 docker commit 提交掉呢?
也不会。
这个原因其实我们前面已经提到过。容器的镜像操作,比如 docker commit,都是发生在宿主机空间的。而由于 Mount Namespace 的隔离作用,宿主机并不知道这个绑定挂载的存在。所以,在宿主机看来,容器中可读写层的 /test 目录(/var/lib/docker/aufs/mnt/[可读写层 ID]/test),始终是空的。
不过,由于 Docker 一开始还是要创建 /test 这个目录作为挂载点,所以执行了 docker commit 之后,你会发现新产生的镜像里,会多出来一个空的 /test 目录。毕竟,新建目录操作,又不是挂载操作,Mount Namespace 对它可起不到“障眼法”的作用。
验证绑定挂载
结合以上的讲解,我们现在来亲自验证一下:
首先,启动一个 helloworld 容器,给它声明一个 Volume,挂载在容器里的 /test 目录上:
1 | |
容器启动之后,我们来查看一下这个 Volume 的 ID:
1 | |
然后,使用这个 ID,可以找到它在 Docker 工作目录下的 volumes 路径:
1 | |
这个 _data 文件夹,就是这个容器的 Volume 在宿主机上对应的临时目录了。
接下来,我们在容器的 Volume 里,添加一个文件 text.txt:
1 | |
这时,我们再回到宿主机,就会发现 text.txt 已经出现在了宿主机上对应的临时目录里:
1 | |
可是,如果你在宿主机上查看该容器的可读写层,虽然可以看到这个 /test 目录,但其内容是空的(关于如何找到这个 AuFS 文件系统的路径,请参考我上一次分享的内容):
1 | |
可以确认,容器 Volume 里的信息,并不会被 docker commit 提交掉;但这个挂载点目录 /test 本身,则会出现在新的镜像当中。
以上内容,就是 Docker Volume 的核心原理了。
使用volume
使用docker volume ls 查看已经存在的volumes
1 | |
创建一个新的volume
1 | |
默认创建在/var/lib/docker/volume/目录下
创建容器时使用该目录进行挂载
1 | |
这样就将新建的容器busybox中的/mydata 目录挂载到了目录/var/lib/docker/volume/myvolume/_data下,在mydata中的操作其实都是在_data中的操作。可以验证,在容器中的/mydata目录下创建一个test.txt文件,在主机中的_data 目录下也会出现test.txt文件。
即时将busybox 容器删除,_data 目录下的文件也不会消失,再创建一个同样的容器,也挂载该目录,在新创建的容器中依然可以观察到test.txt文件。
采用卷(volume),可以很好地实现容器之间的业务共享,比如一个nginx服务容器的日志,需要另外一个单独的日志解析程序来处理,这就需要共享日志文件的存储目录。这也是一个很典型的应用场景。
--volume-from + [已经启动的容器名] 参数,可以实现启动run 新的容器时,挂载已经存在的容器的卷。
文件存储:AUFS
ubuntu Debain
写时复制:在容器中,只有需要修改某个文件时,才会把文件从镜像层复制到容器层。而不会去修改镜像层的文件内容。
我们知道,Docker 主要是基于 Namespace、cgroups 和联合文件系统这三大核心技术实现的。前面的课时我详细讲解了 Namespace 和 cgroups 的相关原理,那么你知道联合文件系统是什么吗?它的原理又是什么呢?
首先我们来了解一下什么是联合文件系统。
什么是联合文件系统
联合文件系统(Union File System,Unionfs)是一种分层的轻量级文件系统,它可以把多个目录内容联合挂载到同一目录下,从而形成一个单一的文件系统,这种特性可以让使用者像是使用一个目录一样使用联合文件系统。
那联合文件系统对于 Docker 是一个怎样的存在呢?它可以说是 Docker 镜像和容器的基础,因为它可以使 Docker 可以把镜像做成分层的结构,从而使得镜像的每一层可以被共享。例如两个业务镜像都是基于 CentOS 7 镜像构建的,那么这两个业务镜像在物理机上只需要存储一次 CentOS 7 这个基础镜像即可,从而节省大量存储空间。
说到这儿,你有没有发现,联合文件系统只是一个概念,真正实现联合文件系统才是关键,那如何实现呢?其实实现方案有很多,Docker 中最常用的联合文件系统有三种:AUFS、Devicemapper 和 OverlayFS。
今天我主要讲解 Docker 中最常用的联合文件系统里的 AUFS,为什么呢?因为 AUFS 是 Docker 最早使用的文件系统驱动,多用于 Ubuntu 和 Debian 系统中。在 Docker 早期,OverlayFS 和 Devicemapper 相对不够成熟,AUFS 是最早也是最稳定的文件系统驱动。 Devicemapper 和 OverlayFS 联合文件系统。
接下来,我们就看看如何配置 Docker 的 AUFS 模式.
如何配置 Docker 的 AUFS 模式
AUFS 目前并未被合并到 Linux 内核主线,因此只有 Ubuntu 和 Debian 等少数操作系统支持 AUFS。你可以使用以下命令查看你的系统是否支持 AUFS:
1 | |
执行以上命令后,如果输出结果包含aufs,则代表当前操作系统支持 AUFS。AUFS 推荐在 Ubuntu 或 Debian 操作系统下使用,如果你想要在 CentOS 等操作系统下使用 AUFS,需要单独安装 AUFS 模块(生产环境不推荐在 CentOS 下使用 AUFS,如果你想在 CentOS 下安装 AUFS 用于研究和测试,可以参考这个链接),安装完成后使用上述命令输出结果中有aufs即可。
当确认完操作系统支持 AUFS 后,你就可以配置 Docker 的启动参数了。
先在 /etc/docker 下新建 daemon.json 文件,并写入以下内容:
1 | |
然后使用以下命令重启 Docker:
1 | |
Docker 重启以后使用docker info命令即可查看配置是否生效:
1 | |
可以看到 Storage Driver 已经变为 aufs,证明配置已经生效,配置生效后就可以使用 AUFS 为 Docker 提供联合文件系统了。
配置好 Docker 的 AUFS 联合文件系统后,你一定很好奇 AUFS 到底是如何工作的呢?下面我带你详细学习一下 AUFS 的工作原理。
AUFS 工作原理
AUFS 是如何存储文件的?
AUFS 是联合文件系统,意味着它在主机上使用多层目录存储,每一个目录在 AUFS 中都叫作分支,而在 Docker 中则称之为层(layer),但最终呈现给用户的则是一个普通单层的文件系统,我们把多层以单一层的方式呈现出来的过程叫作联合挂载。
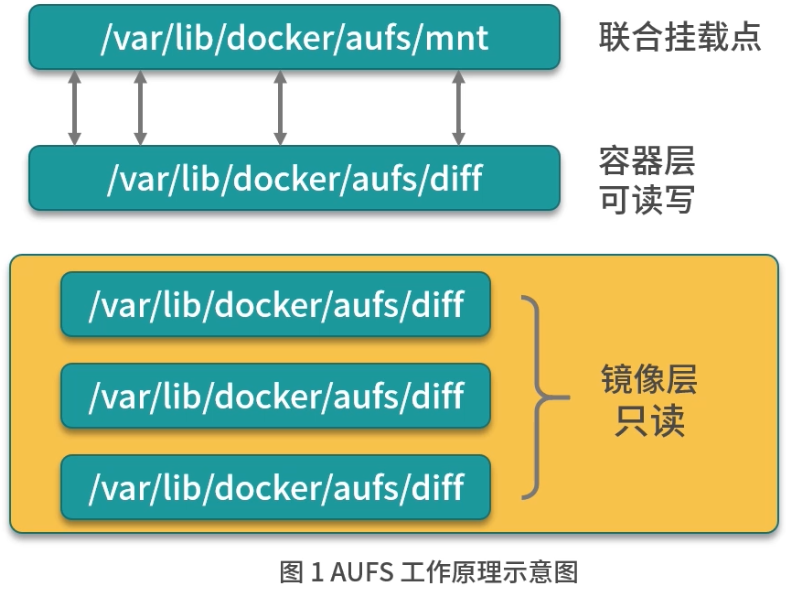
如上图,每一个镜像层和容器层都是/var/lib/docker下的一个子目录,镜像层和容器层都在 aufs/diff 目录下,每一层的目录名称是镜像或容器的 ID 值,联合挂载点在aufs/mnt目录下,mnt 目录是真正的容器工作目录。
下面我们针对 aufs 文件夹下的各目录结构,在创建容器前后的变化做详细讲述。
当一个镜像未生成容器时,AUFS 的存储结构如下。
- diff 文件夹:存储镜像内容,每一层都存储在以镜像层 ID 命名的子文件夹中。
- layers 文件夹:存储镜像层关系的元数据,在 diff 文件夹下的每个镜像层在这里都会有一个文件,文件的内容为该层镜像的父级镜像的 ID。
- mnt 文件夹:联合挂载点目录,未生成容器时,该目录为空。
当一个镜像已经生成容器时,AUFS 存储结构会发生如下变化。
diff 文件夹:当容器运行时,会在 diff 目录下生成容器层。
layers 文件夹:增加容器层相关的元数据。
mnt 文件夹:容器的联合挂载点,这和容器中看到的文件内容一致。
以上便是 AUFS 的工作原理,那你知道容器的在工作过程中是如何使用 AUFS 的吗?
AUFS 对文件的操作
AUFS 的工作过程中对文件的操作分为读取文件和修改文件。下面我们分别来看下 AUFS 对于不同的文件操作是如何工作的。
- 读取文件
当我们在容器中读取文件时,可能会有以下场景。
文件在容器层中存在时:当文件存在于容器层时,直接从容器层读取。
当文件在容器层中不存在时:当容器运行时需要读取某个文件,如果容器层中不存在时,则从镜像层查找该文件,然后读取文件内容。
文件既存在于镜像层,又存在于容器层:当我们读取的文件既存在于镜像层,又存在于容器层时,将会从容器层读取该文件。
- 修改文件或目录
AUFS 对文件的修改采用的是写时复制的工作机制,这种工作机制可以最大程度节省存储空间。具体的文件操作机制如下。
第一次修改文件:当我们第一次在容器中修改某个文件时,AUFS 会触发写时复制操作,AUFS 首先从镜像层复制文件到容器层,然后再执行对应的修改操作。
AUFS 写时复制的操作将会复制整个文件,如果文件过大,将会大大降低文件系统的性能,因此当我们有大量文件需要被修改时,AUFS 可能会出现明显的延迟。好在,写时复制操作只在第一次修改文件时触发,对日常使用没有太大影响。
删除文件或目录:当文件或目录被删除时,AUFS 并不会真正从镜像中删除它,因为镜像层是只读的,AUFS 会创建一个特殊的文件或文件夹,这种特殊的文件或文件夹会阻止容器的访问。
AUFS 演示
准备演示目录和文件
首先我们在 /tmp 目录下创建 aufs 目录:
1 | |
准备挂载点目录:
1 | |
接下来准备容器层内容:
1 | |
最后准备镜像层内容:
1 | |
准备好的目录和文件结构如下:
1 | |
创建 AUFS 联合文件系统
使用 mount 命令可以创建 AUFS 类型的文件系统,命令如下:
1 | |
mount 命令创建 AUFS 类型文件系统时,这里要注意,dirs 参数第一个冒号默认为读写权限,后面的目录均为只读权限,与 Docker 容器使用 AUFS 的模式一致。
执行完上述命令后,mnt 变成了 AUFS 的联合挂载目录,我们可以使用 mount 命令查看一下已经创建的 AUFS 文件系统:
1 | |
我们每创建一个 AUFS 文件系统,AUFS 都会为我们生成一个 ID,这个 ID 在/sys/fs/aufs/会创建对应的目录,在这个 ID 的目录下可以查看文件挂载的权限。
1 | |
可以看到 container1 目录的权限为 rw(代表可读写),image1 和 image2 的权限为 ro(代表只读)。
为了验证 mnt 目录下可以看到 container1、image1 和 image2 目录下的所有内容,我们使用 ls 命令查看一下 mnt 目录:
1 | |
可以看到 mnt 目录下已经出现了我们准备的所有镜像层和容器层的文件。下面让我们来验证一下 AUFS 的写时复制。
验证 AUFS 的写时复制
AUFS 的写时复制是指在容器中,只有需要修改某个文件时,才会把文件从镜像层复制到容器层,下面我们通过修改联合挂载目录 mnt 下的内容来验证下这个过程。
我们使用以下命令修改 mnt 目录下的 image1.txt 文件:
1 | |
然后我们查看下 image1/image1.txt 文件内容:
1 | |
发现“镜像层”的 image1.txt 文件并未被修改。
然后我们查看一下”容器层”对应的 image1.txt 文件内容:
1 | |
发现 AUFS 在“容器层”自动创建了 image1.txt 文件,并且内容为我们刚才写入的内容。至此,我们完成了 AUFS 写时复制的验证。我们在第一次修改镜像内某个文件时,AUFS 会复制这个文件到容器层,然后在容器层对该文件进行修改操作,这就是 AUFS 最典型的特性写时复制。
AUFS为什么一直没有进入Linux内核主线? 可读性太差。。
文件存储驱动:Devicemapper
CentOS
前面学习了什么是联合文件系统,以及 AUFS 的工作原理和配置。我们知道 AUFS 并不在 Linux 内核主干中,所以如果你的操作系统是 CentOS,就不推荐使用 AUFS 作为 Docker 的联合文件系统了。
那在 CentOS 系统中,我们怎么实现镜像和容器的分层结构呢?我们通常使用 Devicemapper 作为 Docker 的联合文件系统。
什么是 Devicemapper
Devicemapper 是 Linux 内核提供的框架,从 Linux 内核 2.6.9 版本开始引入,Devicemapper 与 AUFS 不同,AUFS 是一种文件系统,而Devicemapper 是一种映射块设备的技术框架。
Devicemapper 提供了一种将物理块设备映射到虚拟块设备的机制,目前 Linux 下比较流行的 LVM (Logical Volume Manager 是 Linux 下对磁盘分区进行管理的一种机制)和软件磁盘阵列(将多个较小的磁盘整合成为一个较大的磁盘设备用于扩大磁盘存储和提供数据可用性)都是基于 Devicemapper 机制实现的。
那么 Devicemapper 究竟是如何实现的呢?下面我们首先来了解一下它的关键技术。
Devicemapper 的关键技术
Devicemapper 将主要的工作部分分为用户空间和内核空间。
- 用户空间负责配置具体的设备映射策略与相关的内核空间控制逻辑,例如逻辑设备 dma 如何与物理设备 sda 相关联,怎么建立逻辑设备和物理设备的映射关系等。
- 内核空间则负责用户空间配置的关联关系实现,例如当 IO 请求到达虚拟设备 dm a 时,内核空间负责接管 IO 请求,然后处理和过滤这些 IO 请求并转发到具体的物理设备 sda 上。
这个架构类似于 C/S (客户端/服务区)架构的工作模式,客户端负责具体的规则定义和配置下发,服务端根据客户端配置的规则来执行具体的处理任务。
Devicemapper 的工作机制主要围绕三个核心概念
- 映射设备(mapped device):即对外提供的逻辑设备,它是由 Devicemapper 模拟的一个虚拟设备,并不是真正存在于宿主机上的物理设备。
- 目标设备(target device):目标设备是映射设备对应的物理设备或者物理设备的某一个逻辑分段,是真正存在于物理机上的设备。
- 映射表(map table):映射表记录了映射设备到目标设备的映射关系,它记录了映射设备在目标设备的起始地址、范围和目标设备的类型等变量。
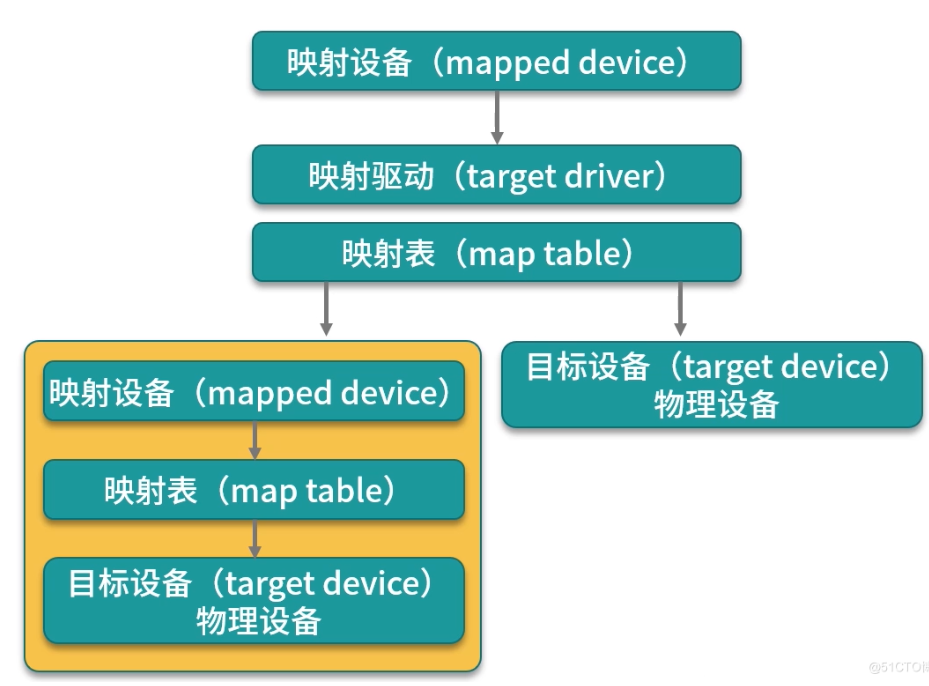
Devicemapper 三个核心概念之间的关系如图 ,映射设备通过映射表关联到具体的物理目标设备。事实上,映射设备不仅可以通过映射表关联到物理目标设备,也可以关联到虚拟目标设备,然后虚拟目标设备再通过映射表关联到物理目标设备。
Devicemapper 在内核中通过很多模块化的映射驱动(target driver)插件实现了对真正 IO 请求的拦截、过滤和转发工作,比如 Raid、软件加密、瘦供给(Thin Provisioning)等。其中瘦供给模块是 Docker 使用 Devicemapper 技术框架中非常重要的模块,下面我们来详细了解下**瘦供给(Thin Provisioning)**。
瘦供给(Thin Provisioning)
瘦供给的意思是动态分配,这跟传统的固定分配不一样。传统的固定分配是无论我们用多少都一次性分配一个较大的空间,这样可能导致空间浪费。而瘦供给是我们需要多少磁盘空间,存储驱动就帮我们分配多少磁盘空间。
这种分配机制就好比我们一群人围着一个大锅吃饭,负责分配食物的人每次都给你一点分量,当你感觉食物不够时再去申请食物,而当你吃饱了就不需要再去申请食物了,从而避免了食物的浪费,节约的食物可以分配给更多需要的人。
那么,你知道 Docker 是如何使用瘦供给来做到像 AUFS 那样分层存储文件的吗?答案就是: Docker 使用了瘦供给的快照(snapshot)技术。
什么是快照(snapshot)技术
这是全球网络存储工业协会 SNIA(StorageNetworking Industry Association)对快照(Snapshot)的定义:
关于指定数据集合的一个完全可用拷贝,该拷贝包括相应数据在某个时间点(拷贝开始的时间点)的映像。快照可以是其所表示的数据的一个副本,也可以是数据的一个复制品。
简单来说,快照是数据在某一个时间点的存储状态。快照的主要作用是对数据进行备份,当存储设备发生故障时,可以使用已经备份的快照将数据恢复到某一个时间点,而 Docker 中的数据分层存储也是基于快照实现的。
以上便是实现 Devicemapper 的关键技术,那 Docker 究竟是如何使用 Devicemapper 实现存储数据和镜像分层共享的呢?
Devicemapper 是如何数据存储的
当 Docker 使用 Devicemapper 作为文件存储驱动时,Docker 将镜像和容器的文件存储在瘦供给池(thinpool)中,并将这些内容挂载在 /var/lib/docker/devicemapper/ 目录下。
这些目录储存 Docker 的容器和镜像相关数据,目录的数据内容和功能说明如下。
- devicemapper 目录(
/var/lib/docker/devicemapper/devicemapper/):存储镜像和容器实际内容,该目录由一个或多个块设备构成。 - metadata 目录(
/var/lib/docker/devicemapper/metadata/): 包含 Devicemapper 本身配置的元数据信息, 以 json 的形式配置,这些元数据记录了镜像层和容器层之间的关联信息。 - mnt 目录(
/var/lib/docker/devicemapper/mnt/):是容器的联合挂载点目录,未生成容器时,该目录为空,而容器存在时,该目录下的内容跟容器中一致。
Devicemapper 如何实现镜像分层与共享
Devicemapper 使用专用的块设备实现镜像的存储,并且像 AUFS 一样使用了写时复制的技术来保障最大程度节省存储空间,所以 Devicemapper 的镜像分层也是依赖快照来是实现的。
Devicemapper 的每一镜像层都是其下一层的快照,最底层的镜像层是我们的瘦供给池,通过这种方式实现镜像分层有以下优点。
相同的镜像层,仅在磁盘上存储一次。例如,我有 10 个运行中的 busybox 容器,底层都使用了 busybox 镜像,那么 busybox 镜像只需要在磁盘上存储一次即可。
快照是写时复制策略的实现,也就是说,当我们需要对文件进行修改时,文件才会被复制到读写层。
注意,更新一个
1GB文件的32KB数据只复制一个64KB数据块到容器快照。这比在文件级别操作需要复制整个1GB文件到容器数据层有明显的性能优势。不过在实践中,当容器执行很多小于
64KB的写操作时,devicemapper的性能会比AUFS要差。相比对文件系统加锁的机制,Devicemapper 工作在块级别,因此可以实现同时修改和读写层中的多个块设备,比文件系统效率更高。
当我们需要读取数据时,如果数据存在底层快照中,则向底层快照查询数据并读取。当我们需要写数据时,则向瘦供给池动态申请存储空间生成读写层,然后把数据复制到读写层进行修改。Devicemapper 默认每次申请的大小是 64K 或者 64K 的倍数,因此每次新生成的读写层的大小都是 64K 或者 64K 的倍数。
对于写操作较大的,可以采用挂载 data volumes。使用 data volumes 可以绕过存储驱动,从而避免 thin provisioning 和 copy-on-write 引入的额外开销。
以下是一个运行中的 Ubuntu 容器示意图。

这个 Ubuntu 镜像一共有四层,每一层镜像都是下一层的快照,镜像的最底层是基础设备的快照。当容器运行时,容器是基于镜像的快照。综上,Devicemapper 实现镜像分层的根本原理就是快照。
接下来,我们看下如何配置 Docker 的 Devicemapper 模式。
如何在 Docker 中配置 Devicemapper
Docker 的 Devicemapper 模式有两种:第一种是 loop-lvm 模式,该模式主要用来开发和测试使用;第二种是 direct-lvm 模式,该模式推荐在生产环境中使用。
LVM是什么
LVM是 Logical Volume Manager,逻辑的概念,Linux用户安装Linux操作系统时遇到的一个常见的难以决定的问题就是如何正确地评估各分区大小,以分配合适的硬盘空间。普通的磁盘分区管理方式在逻辑分区划分好之后就无法改变其大小,当一个逻辑分区存放不下某个文件时,这个文件因为受上层文件系统的限制,也不能跨越多个分区来存放,所以也不能同时放到别的磁盘上。而遇到出现某个分区空间耗尽时,解决的方法通常是使用符号链接,或者使用调整分区大小的工具,但这只是暂时解决办法,没有从根本上解决问题。随着Linux的逻辑卷管理功能的出现,这些问题都迎刃而解,用户在无需停机的情况下可以方便地调整各个分区大小。
PV,VG,LV构成了一种易于管理拥有一个或多个硬盘的主机的文件系统,这些硬盘可能只有一个分区也可能有多个。通过将这些物理存在的分区(或称为卷)PV(physical volume)进行整合,组成一个分区(卷)组VG(volume group),进而再次进行分配形成逻辑分区(卷)LV(logical volume)。创建成功的逻辑分区对于操作系统来说会想普通分区无异,其好处是可以动态调整分区大小。管理PV,VG,LV的工具称为逻辑卷管理器LVM(logical volume manager)。如下图所示:
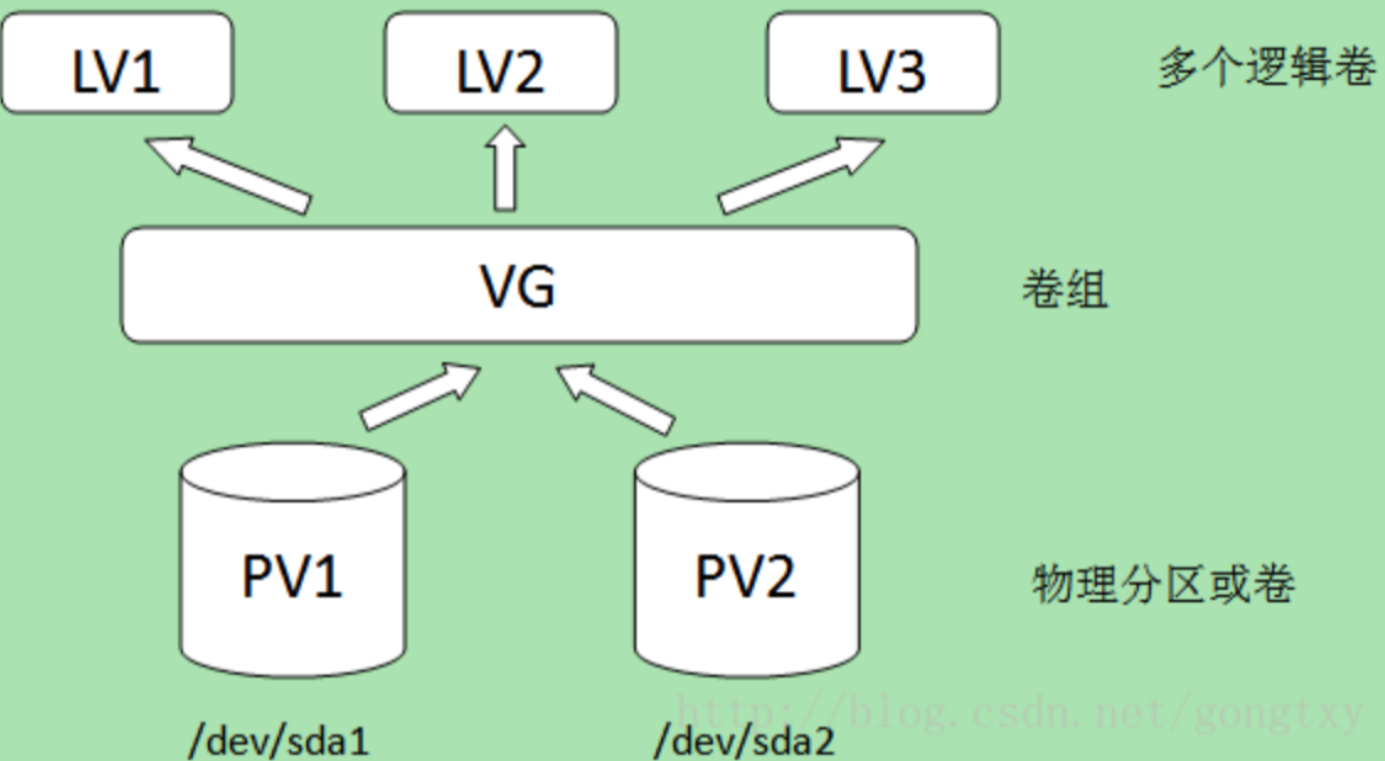
需要指出的是,在某个物理卷在加入卷组时,会将物理卷的最小存储单元设定为一个固定的值,这个值称为PE(physical extent)。这个值的创建,是为了保证用统一的最小分配单元来创建逻辑卷,不至于因为分配单元大小不同而造成空间浪费。举个例子:用于远洋运输的集装箱的设计是是有着统一标准的,最重要一点是集装箱大小完全相同,这样做的好处是集装箱相互堆叠在一起不会留下多余的空隙,完全利用了空间,且便于管理。设定PE的原因也与此相同。LVM以最小分配单元来创建逻辑卷,该最小分配单元的值称为LE(logical extent)。一般来说PE=LE,PE的大小是可配置的,默认为4MB。
下面我们逐一配置,首先来看下如何配置 loop-lvm 模式。
配置 loop-lvm 模式
这个模式使用空闲文件来构建存储池,性能非常低
1.使用以下命令停止已经运行的 Docker:
1 | |
2.编辑 /etc/docker/daemon.json 文件,如果该文件不存在,则创建该文件,并添加以下配置:
1 | |
3.启动 Docker:
1 | |
4.验证 Docker 的文件驱动模式:
1 | |
可以看到 Storage Driver 为 devicemapper,这表示 Docker 已经被配置为 Devicemapper 模式。
但是这里输出的 Data file 为 /dev/loop0,这表示我们目前在使用的模式为 loop-lvm。但是由于 loop-lvm 性能比较差,因此不推荐在生产环境中使用 loop-lvm 模式。下面我们看下生产环境中应该如何配置 Devicemapper 的 direct-lvm 模式。
配置 direct-lvm 模式
使用块设备来构建精简池来存放镜像和容器的数据。
- 使用以下命令停止已经运行的 Docker:
1 | |
- 编辑
/etc/docker/daemon.json文件,如果该文件不存在,则创建该文件,并添加以下配置:
1 | |
其中 directlvm_device 指定需要用作 Docker 存储的磁盘路径,Docker 会动态为我们创建对应的存储池。例如这里我想把 /dev/xdf 设备作为我的 Docker 存储盘,directlvm_device 则配置为 /dev/xdf。
- 启动 Docker:
1 | |
- 验证 Docker 的文件驱动模式:
1 | |
当我们看到 Storage Driver 为 devicemapper,并且 Pool Name 为 docker-thinpool 时,这表示 Devicemapper 的 direct-lvm 模式已经配置成功。
结语
Devicemapper 使用块设备来存储文件,运行速度会比直接操作文件系统更快,因此很长一段时间内在 Red Hat 或 CentOS 系统中,Devicemapper 一直作为 Docker 默认的联合文件系统驱动,为 Docker 在 Red Hat 或 CentOS 稳定运行提供强有力的保障。
早期的Docker运行在Ubuntu和Debian Linux上并使用AUFS作为后端存储。Docker流行之后,越来越多的的公司希望在Red Hat Enterprise Linux这类企业级的操作系统上面运行Docker,但可惜的是RHEL的内核并不支持AUFS。这个时候红帽公司出手了,决定和Docker公司合作去开发一种基于Device Mapper技术的后端存储,也就是现在的devicemapper。
overlayFS
OverlayFS 的发展分为两个阶段。2014 年,OverlayFS 第一个版本被合并到 Linux 内核 3.18 版本中,此时的 OverlayFS 在 Docker 中被称为overlay文件驱动。由于第一版的overlay文件系统存在很多弊端(例如运行一段时间后Docker 会报 “too many links problem” 的错误), Linux 内核在 4.0 版本对overlay做了很多必要的改进,此时的 OverlayFS 被称之为overlay2。
因此,在 Docker 中 OverlayFS 文件驱动被分为了两种,一种是早期的overlay,不推荐在生产环境中使用,另一种是更新和更稳定的overlay2,推荐在生产环境中使用。下面的内容我们主要围绕overlay2展开。
使用 overlay2 的先决条件
overlay2虽然很好,但是它的使用是有一定条件限制的。
要想使用overlay2,Docker 版本必须高于 17.06.02。
如果你的操作系统是 RHEL 或 CentOS,Linux 内核版本必须使用 3.10.0-514 或者更高版本,其他 Linux 发行版的内核版本必须高于 4.0(例如 Ubuntu 或 Debian),你可以使用uname -a查看当前系统的内核版本。
overlay2最好搭配 xfs 文件系统使用,并且使用 xfs 作为底层文件系统时,d_type必须开启。
一些前置知识
xfs文件系统的 d_type是什么
d_type 是 Linux 内核的一个术语,表示 “目录条目类型”,而目录条目,其实是文件系统上目录信息的一个数据结构。d_type,就是这个数据结构的一个字段,这个字段用来表示文件的类型,是文件,还是管道,还是目录还是套接字等。
d_type 从 Linux 2.6 内核开始就已经支持了,只不过虽然 Linux 内核虽然支持,但有些文件系统实现了 d_type,而有些,没有实现,有些是选择性的实现,也就是需要用户自己用额外的参数来决定是否开启d_type的支持。
为什么docker在overlay2(xfs文件系统)需要d_type
不论是 overlay,还是 overlay2,它们的底层文件系统都是 overlayfs 文件系统。而 overlayfs 文件系统,就会用到 d_type 这个东西用来文件的操作是被正确的处理了。换句话说,docker只要使用 overlay 或者 overlay2,就等于在用 overlayfs,也就一定会用到 d_type。所以,docker 提供了
docker info命令来检测你docker服务,是否在使用overlay的时候正确的使用 d_type。如果用了 overlay/overlay2,但 d_type 没有开,就报警告。如果在不支持 d_type 的 overlay/overlay 驱动下使用docker,也就意味着 docker 在操作文件的时候,可能会遇到一些错误,比如 无法删除某些目录或文件,设置文件或目录的权限或用户失败等等。这些都是不可预料的错误。举个具体的场景,就是,docker构建的时候,可能在构建过程中,删除文件等操作失败,导致构建停止。
可以使用以下命令验证 d_type 是否开启:
1
2$ xfs_info /var/lib/docker | grep ftype
naming =version 2 bsize=4096 ascii-ci=0 ftype=1当输出结果中有 ftype=1 时,表示 d_type 已经开启。如果你的输出结果为 ftype=0,则需要重新格式化磁盘目录,命令如下:
1
$ sudo mkfs.xfs -f -n ftype=1 /path/to/disk另外,在生产环境中,推荐挂载
/var/lib/docker目录到单独的磁盘或者磁盘分区,这样可以避免该目录写满影响主机的文件写入,并且把挂载信息写入到/etc/fstab,防止机器重启后挂载信息丢失。挂载配置中推荐开启
pquota,这样可以防止某个容器写文件溢出导致整个容器目录空间被占满。写入到/etc/fstab中的内容如下:1
$UUID /var/lib/docker xfs defaults,pquota 0 0其中 UUID 为
/var/lib/docker所在磁盘或者分区的 UUID 或者磁盘路径。如果你的操作系统无法满足上面的任何一个条件,那我推荐你使用 AUFS 或者 Devicemapper 作为你的 Docker 文件系统驱动。
通常情况下, overlay2 会比 AUFS 和 Devicemapper 性能更好,而且更加稳定,因为 overlay2 在 inode 优化上更加高效。因此在生产环境中推荐使用 overlay2 作为 Docker 的文件驱动。
下面通过实例,学习如何初始化
/var/lib/docker目录,为后面配置 Docker 的overlay2文件驱动做准备。
准备 /var/lib/docker 目录
- 使用 lsblk(Linux 查看磁盘和块设备信息命令)命令查看本机磁盘信息:
1 | |
可以看到,我的机器有两块磁盘,一块是 vda,一块是 vdb。其中 vda 已经被用来挂载系统根目录,这里我想把 /var/lib/docker 挂载到 vdb1 分区上。
使用 mkfs 命令格式化磁盘 vdb1:
1
$ sudo mkfs.xfs -f -n ftype=1 /dev/vdb1将挂载信息写入到
/etc/fstab,保证机器重启挂载目录不丢失:1
$ sudo echo "/dev/vdb1 /var/lib/docker xfs defaults,pquota 0 0" >> /etc/fstab使用 mount 命令使得挂载目录生效:
1
$ sudo mount -a查看挂载信息:
1
2
3
4
5
6$ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
vda 253:0 0 500G 0 disk
`-vda1 253:1 0 500G 0 part /
vdb 253:16 0 500G 0 disk
`-vdb1 253:17 0 8G 0 part /var/lib/docker可以看到此时
/var/lib/docker目录已经被挂载到了 vdb1 这个磁盘分区上。我们使用 xfs_info 命令验证下 d_type 是否已经成功开启:1
2$ xfs_info /var/lib/docker | grep ftype
naming =version 2 bsize=4096 ascii-ci=0 ftype=1可以看到输出结果为 ftype=1,证明 d_type 已经被成功开启。
准备好/var/lib/docker 目录后,我们就可以配置 Docker 的文件驱动为 overlay2,并且启动 Docker 了。
如何在 Docker 中配置 overlay2?
当你的系统满足上面的条件后,就可以配置你的 Docker 存储驱动为 overlay2 了,具体配置步骤如下。
停止已经运行的 Docker:
1
$ sudo systemctl stop docker备份
/var/lib/docker目录:1
$ sudo cp -au /var/lib/docker /var/lib/docker.back在
/etc/docker目录下创建 daemon.json 文件,如果该文件已经存在,则修改配置为以下内容:1
2
3
4
5
6
7{
"storage-driver": "overlay2",
"storage-opts": [
"overlay2.size=20G",
"overlay2.override_kernel_check=true"
]
}其中 storage-driver 参数指定使用 overlay2 文件驱动,overlay2.size 参数表示限制每个容器根目录大小为 20G。限制每个容器的磁盘空间大小是通过 xfs 的 pquota 特性实现,overlay2.size 可以根据不同的生产环境来设置这个值的大小。我推荐你在生产环境中开启此参数,防止某个容器写入文件过大,导致整个 Docker 目录空间溢出。
启动 Docker:
1
$ sudo systemctl start docker检查配置是否生效:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16$ docker info
Client:
Debug Mode: false
Server:
Containers: 1
Running: 0
Paused: 0
Stopped: 1
Images: 1
Server Version: 19.03.12
Storage Driver: overlay2
Backing Filesystem: xfs
Supports d_type: true
Native Overlay Diff: true
Logging Driver: json-file
Cgroup Driver: cgroupfs ... 省略部分无用输出可以看到 Storage Driver 已经变为 overlay2,并且 d_type 也是 true。至此,你的 Docker 已经配置完成。下面我们看下 overlay2 是如何工作的。
overlay2 工作原理
overlay2 是如何存储文件的?
overlay2 和 AUFS 类似,它将所有目录称之为层(layer),overlay2 的目录是镜像和容器分层的基础,而把这些层统一展现到同一的目录下的过程称为联合挂载(union mount)。overlay2 把目录的下一层叫作lowerdir,上一层叫作upperdir,联合挂载后的结果叫作merged。
overlay2 文件系统最多支持 128 个层数叠加,也就是说你的 Dockerfile 最多只能写 128 行,不过这在日常使用中足够了。
下面我们通过拉取一个 Ubuntu 操作系统的镜像来看下 overlay2 是如何存放镜像文件的。
首先,我们通过以下命令拉取 Ubuntu 镜像:
1 | |
可以看到镜像一共被分为四层拉取,拉取完镜像后我们查看一下 overlay2 的目录:
1 | |
可以看到 overlay2 目录下出现了四个镜像层目录和一个l目录,我们首先来查看一下l目录的内容:
1 | |
可以看到l目录是一堆软连接,把一些较短的随机串软连到镜像层的 diff 文件夹下,这样做是为了避免达到mount命令参数的长度限制。
面我们查看任意一个镜像层下的文件内容:
1 | |
镜像层的 link 文件内容为该镜像层的短 ID,diff 文件夹为该镜像层的改动内容,lower 文件为该层的所有父层镜像的短 ID。
我们可以通过docker image inspect命令来查看某个镜像的层级关系,例如我想查看刚刚下载的 Ubuntu 镜像之间的层级关系,可以使用以下命令:
1 | |
其中,MergedDir代表当前镜像层在overlay2存储下的目录。LowerDir代表当前镜像的父层关系,使用:分隔,:最后代表该镜像的最底层。
下面我们将镜像运行起来成为容器:
1 | |
我们使用docker inspect命令来查看一下容器的工作目录:
1 | |
MergedDir 后面的内容即为容器层的工作目录,LowerDir 为容器所依赖的镜像层目录。 然后我们查看下 overlay2 目录下的内容:
1 | |
可以看到 overlay2 目录下增加了容器层相关的目录,我们再来查看一下容器层下的内容:
1 | |
link 和 lower 文件与镜像层的功能一致,link 文件内容为该容器层的短 ID,lower 文件为该层的所有父层镜像的短 ID 。diff 目录为容器的读写层,容器内修改的文件都会在 diff 中出现,merged 目录为分层文件联合挂载后的结果,也是容器内的工作目录。
总体来说,overlay2 是这样储存文件的:overlay2将镜像层和容器层都放在单独的目录,并且有唯一 ID,每一层仅存储发生变化的文件,最终使用联合挂载技术将容器层和镜像层的所有文件统一挂载到容器中,使得容器中看到完整的系统文件。
overlay2 如何读取、修改文件?
overlay2 的工作过程中对文件的操作分为读取文件和修改文件。
读取文件
容器内进程读取文件分为以下三种情况。
- 文件在容器层中存在:当文件存在于容器层并且不存在于镜像层时,直接从容器层读取文件;
- 当文件在容器层中不存在:当容器中的进程需要读取某个文件时,如果容器层中不存在该文件,则从镜像层查找该文件,然后读取文件内容;
- 文件既存在于镜像层,又存在于容器层:当我们读取的文件既存在于镜像层,又存在于容器层时,将会从容器层读取该文件。
修改文件或目录
overlay2 对文件的修改采用的是写时复制的工作机制,这种工作机制可以最大程度节省存储空间。具体的文件操作机制如下。
第一次修改文件:当我们第一次在容器中修改某个文件时,overlay2 会触发写时复制操作,overlay2 首先从镜像层复制文件到容器层,然后在容器层执行对应的文件修改操作。这与AUFS和Devicemapper相同。
overlay2 写时复制的操作将会复制整个文件,如果文件过大,将会大大降低文件系统的性能,因此当我们有大量文件需要被修改时,overlay2 可能会出现明显的延迟。好在,写时复制操作只在第一次修改文件时触发,对日常使用没有太大影响。
这点与AUFS相同
与Devicemapper是否相同??
删除文件或目录:当文件或目录被删除时,overlay2 并不会真正从镜像中删除它,因为镜像层是只读的,overlay2 会创建一个特殊的文件或目录,这种特殊的文件或目录会阻止容器的访问。
结束语
overlay2 目前已经是 Docker 官方推荐的文件系统了,也是目前安装 Docker 时默认的文件系统,因为 overlay2 在生产环境中不仅有着较高的性能,它的稳定性也极其突出。但是 overlay2 的使用还是有一些限制条件的,例如要求 Docker 版本必须高于 17.06.02,内核版本必须高于 4.0 等。因此,在生产环境中,如果你的环境满足使用 overlay2 的条件,请尽量使用 overlay2 作为 Docker 的联合文件系统。
存储驱动的比较
AUFS VS OverlayFS
AUFS和Overlay都是联合文件系统,但AUFS有多层,而Overlay只有两层,所以在做写时复制操作时,如果文件比较大且存在比较低的层,则AUSF可能会慢一些。而且Overlay并入了linux kernel mainline,AUFS没有。目前AUFS已基本被淘汰。
OverlayFS VS Device mapper
OverlayFS是文件级存储,Device mapper是块级存储,当文件特别大而修改的内容很小,Overlay不管修改的内容大小都会复制整个文件,对大文件进行修改显示要比小文件要消耗更多的时间,而块级无论是大文件还是小文件都只复制需要修改的块,并不是整个文件,在这种场景下,显然device mapper要快一些。因为块级的是直接访问逻辑盘,适合IO密集的场景。而对于程序内部复杂,大并发但少IO的场景,Overlay的性能相对要强一些。
常用存储驱动对比
| 存储驱动 | 特点 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| AUFS | 联合文件系统、未并入内核主线、文件级存储 | 作为docker的第一个存储驱动,已经有很长的历史,比较稳定,且在大量的生产中实践过,有较强的社区支持 | 有多层,在做写时复制操作时,如果文件比较大且存在比较低的层,可能会慢一些 | 大并发但少IO的场景 |
| overlayFS | 联合文件系统、并入内核主线、文件级存储 | 只有两层 | 不管修改的内容大小都会复制整个文件,对大文件进行修改显示要比小文件消耗更多的时间 | 大并发但少IO的场景 |
| Devicemapper | 并入内核主线、块级存储 | 块级无论是大文件还是小文件都只复制需要修改的块,并不是整个文件 | 不支持共享存储,当有多个容器读同一个文件时,需要生成多个复本,在很多容器启停的情况下可能会导致磁盘溢出 | 适合io密集的场景 |
| Btrfs | 并入linux内核、文件级存储 | 可以像devicemapper一样直接操作底层设备,支持动态添加设备 | 不支持共享存储,当有多个容器读同一个文件时,需要生成多个复本 | 不适合在高密度容器的paas平台上使用 |
| ZFS | 把所有设备集中到一个存储池中来进行管理 | 支持多个容器共享一个缓存块,适合内存大的环境 | COW使用碎片化问题更加严重,文件在硬盘上的物理地址会变的不再连续,顺序读会变的性能比较差 | 适合paas和高密度的场景 |
Docker Compose
Docker官方的单机多容器管理系统
本质是一个python脚本,通过解析用户编写的yaml文件,调用Docker API实现动态的创建和管理多个容器。
Docker Swarm
管理规模更大的容器集群
- 分布式:Raft协议
- 安全:TLS双向认证
- 简单:从Docker1.12版本后,被内置到了Docker中