Medusa
本文最后更新于:2 个月前
投机采样的挑战
- 寻找理想的草案模型并非易事:确定一个“小而强大”的草案模型,能够与原始模型良好对齐(接受率不能太低),是一项复杂的任务。可能需要重训练与微调。
- 系统复杂性:在一个系统中托管两个(甚至是多个)不同的模型引入了多层复杂性,无论是在计算上还是在操作上,尤其是在分布式环境中。
- 采样效率低下:在进行推断解码抽样时,需要使用一种重要性抽样方案。这给生成过程带来了额外的开销,尤其是在较高的抽样温度下。
Medusa
insight
于是,为了解决前两个挑战,Medusa不采用多个draft model,而是采用同一个model上添加多个解码头,起到与采用多个draft model同样的效果;为了解决第三个挑战,Medusa结合SpecInfer中提到的tree attention策略。
并且在训练时,Medusa可以将多头解冻,模型的别的部分frozen住,起到只训练多头的效果。每个Medusa head实现为一个带有残差连接的单层前馈网络。它们预测多个接下来的标记,而不仅仅是下一个标记。
Medusa中提到的Blockwise Parallel Decoding
18年这篇文章的地址:https://arxiv.org/abs/1811.03115
核心思想:普通的自回归解码前向传播一次,生成一个token。Blockwise Parallel Decoding中使用多个model,model的个数是向后预测的token的个数。
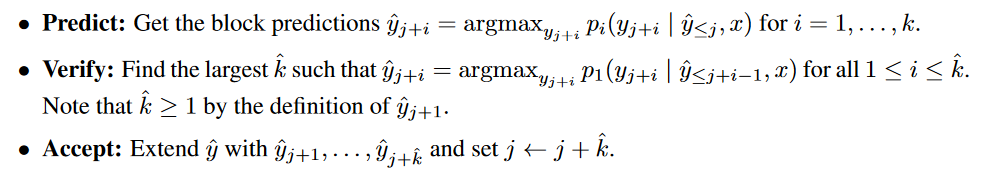
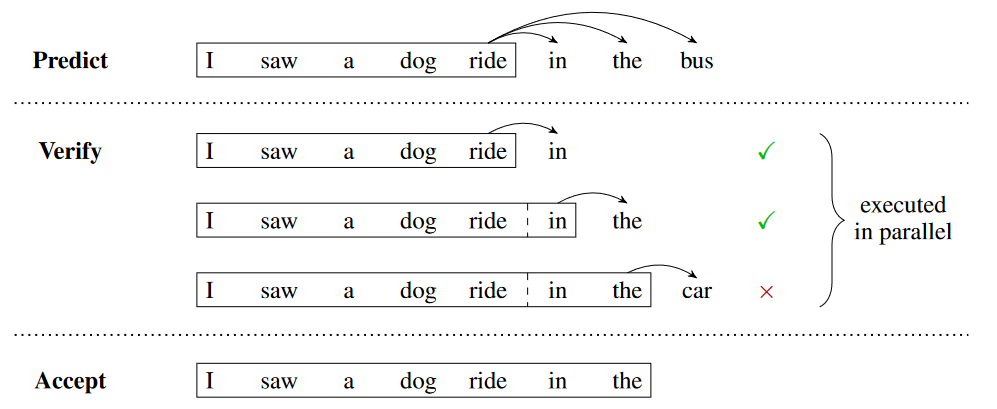
总结就是:使用i个model并行同时生成i个token,找到符合自回归串行贪心采样特征的最大的k,即从第k个的logits中贪心采样,得到的是第k+1个位置的token,符合这样要求的最大的k,就是我们要找的k。
Lookahead decoding
Blog:https://lmsys.org/blog/2023-11-21-lookahead-decoding/
与Medusa的思想类似,同样也参照了18年的论文
基于这样的观察:尽管一步解码多个下一个 token 是不可行的,但 LLM 确实可以并行生成多个不相交的 n-gram。这些 n-gram 可能适合生成序列的未来部分。
于是,Lookahead decoding能够在每一步生成n-grams,而不是只生成一个token,这样可以减少解码步骤的总数:在不到N个步骤的时间内生成N个token。Lookahead decoding的特点:
- 无需草稿模型即可运行,从而简化了部署。
- 相对于每步 log(FLOPs) 线性减少解码步骤数。
Lookahead decoding可以实现以计算开销(迭代计算雅可比矩阵)来换取延迟减少,虽然这会带来收益递减。
使用Jacobi矩阵解决并行解码问题

Jacobi解码
我们展示一种并行解码方式:Jacobi解码的过程如下
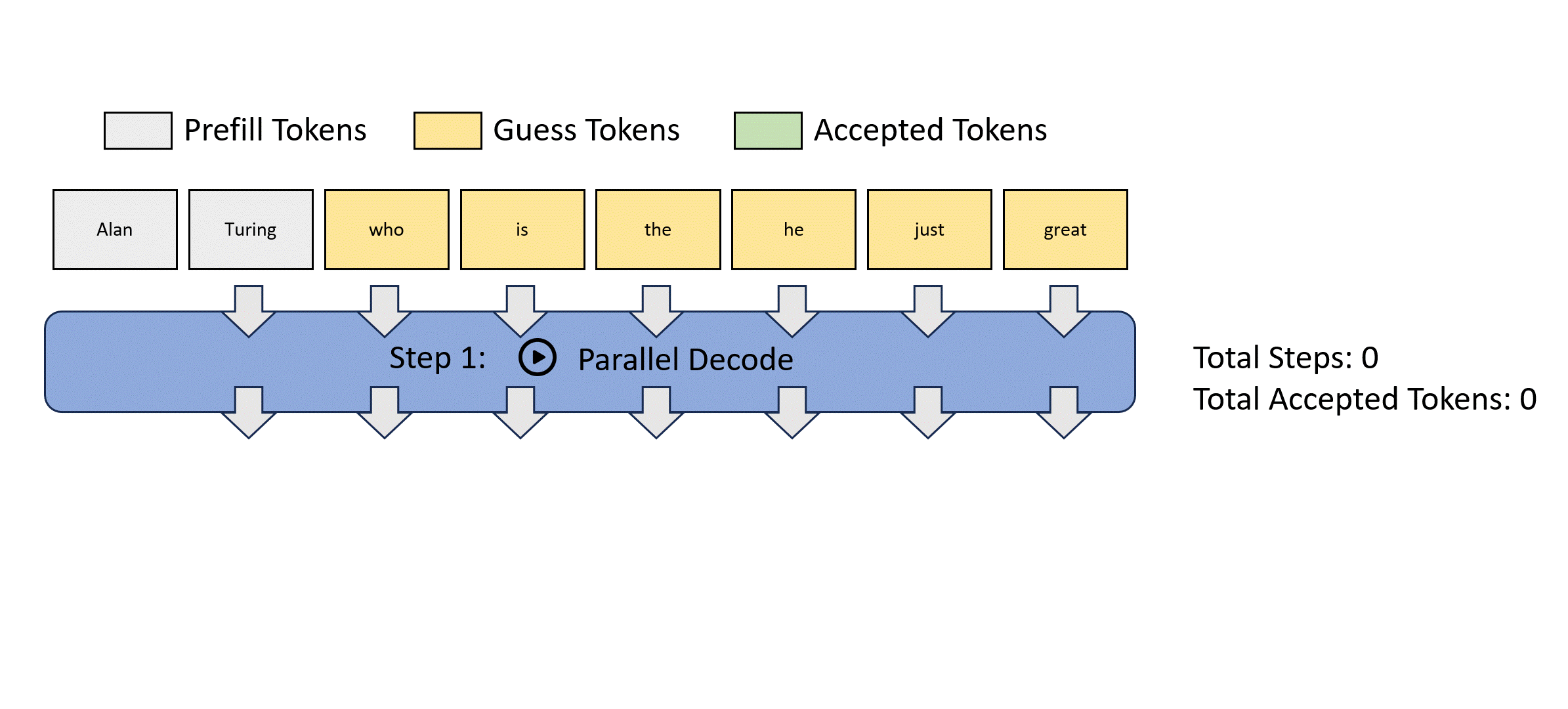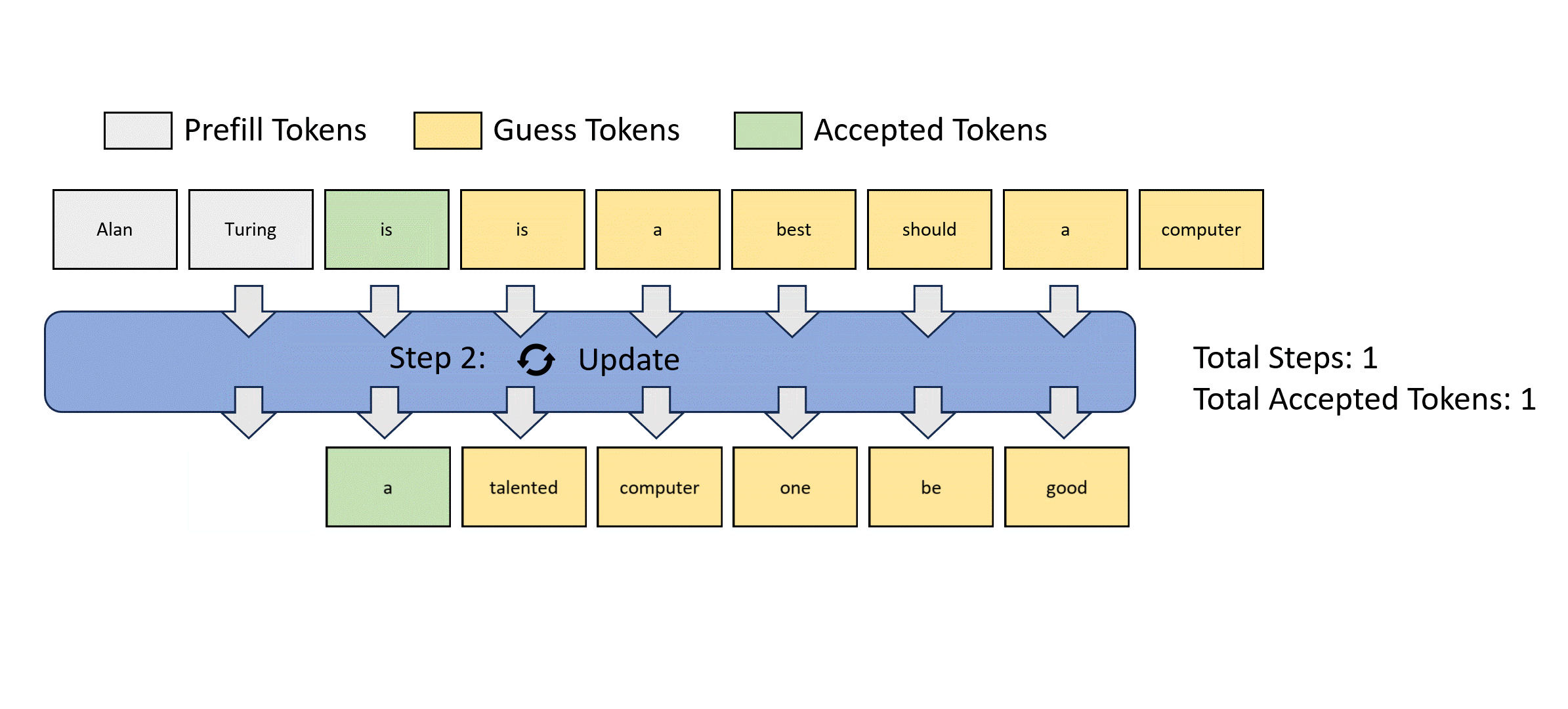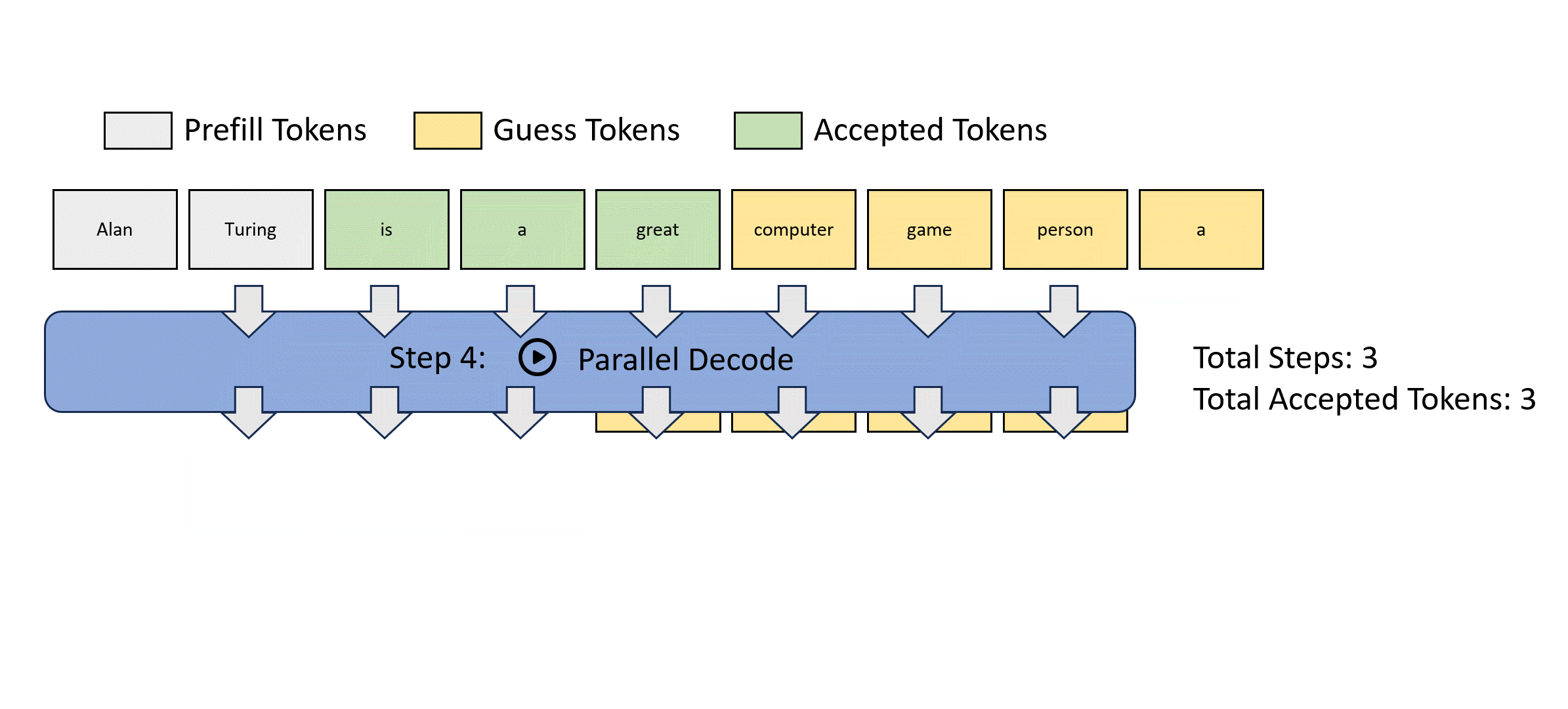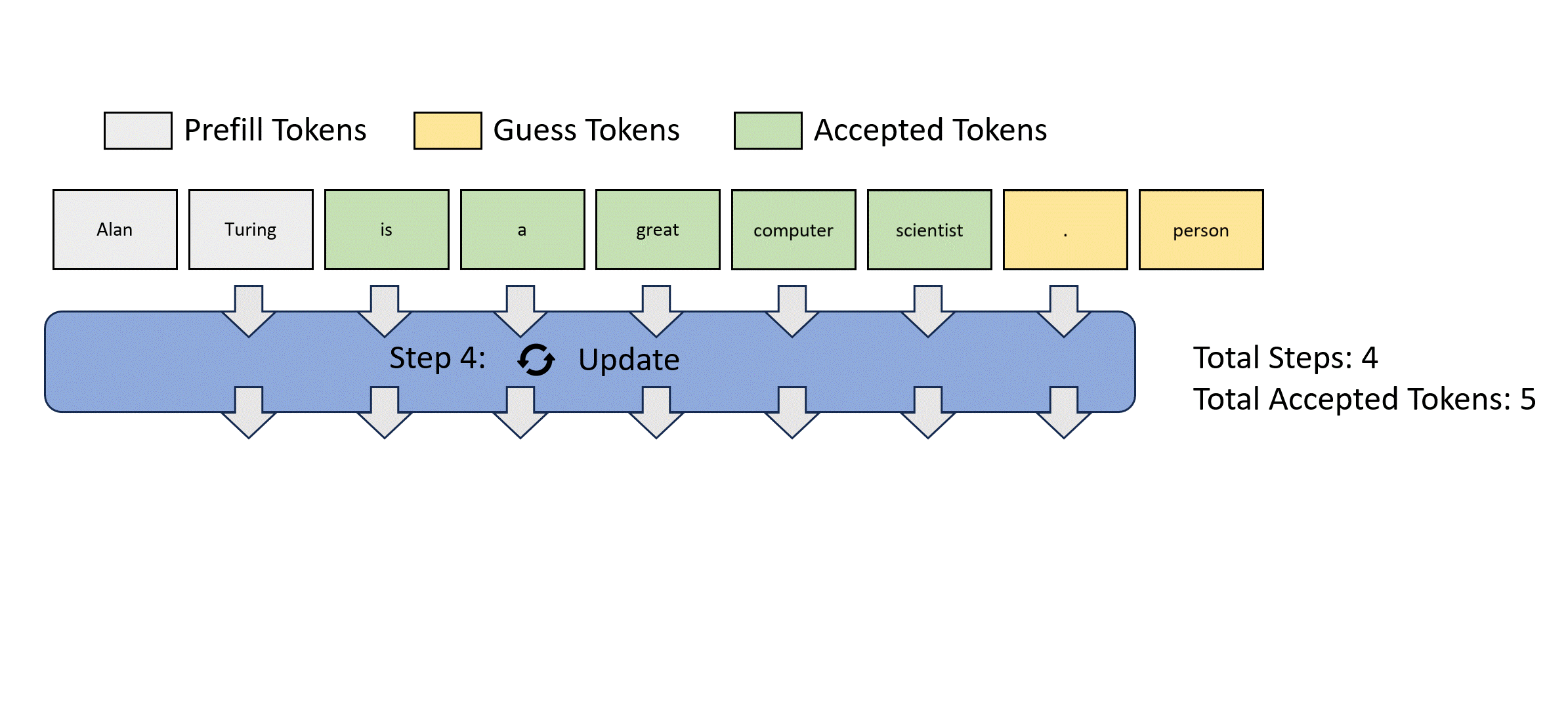
这种方法虽然可以实现一次前向传播生成多个token,但是其正确性很差,违背了并行解码的初衷。
问题:
每次Jacobi解码都是要迭代到一定次数,稳定之后才结束本次解码的吗?这样难道不会带来额外的时延overhead?(这个问题要看代码解决)
Lookahead 解码
我们注意到,每次Jacobi解码都会在每一个token位置上生成一个推理结果对。缓存每次前向传播的结果对,若在verify阶段遇到不匹配的,把确定正确的覆盖掉之后,再从缓存中找是否有新的token匹配的前向传播结果对。
W:lookahead windows size
N:the N-gram size
核心思想:以计算量换低延迟
实验结果表明,在 A100 上,表 1 中的以下配置在大多数情况下运行良好。 7B、13B 和 33B 模型每步分别需要 120x、80x 和 56x 额外的 FLOP。 然而,由于 LLM 解码的内存密集型限制特性,这些额外的 FLOP 只带来很少的每步成本和可见的步压缩比,从而带来显着的加速。
| Model | Window Size (W) | N-gram Size (N) |
|---|---|---|
| 7B | 15 | 5 |
| 13B | 10 | 5 |
| 33B | 7 | 5 |