本文最后更新于:11 小时前
虽然NSL-Spec是为科研手搓的投机推理系统,但经过实测发现多进程存在很大的性能问题。本篇记录一下笔者在打log发现系统性能瓶颈并解决的过程。
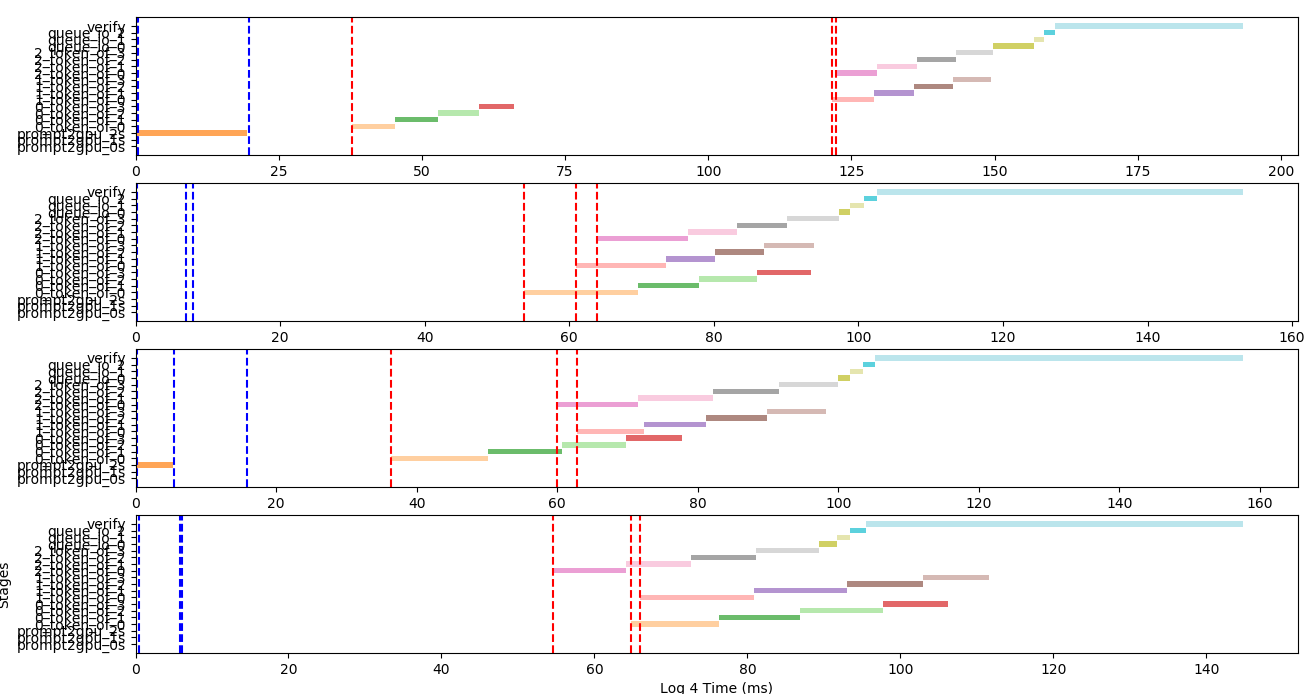
优化进程之间消息传递时间不固定的问题 为了实现多个小模型并行进行自回归推理,同时避开python的GIL问题,故使用多进程加载小模型,每个小模型放置在一个单独的进程上。初步写代码发现小模型推理的time_line如下所示:
其中蓝色线表示把小模型自回归所需数据传输到进程中的时刻,红色线表示小模型自回归推理进程接收到数据的时刻,横轴表示时间,单位是ms,纵轴表示每一个步骤。可以发现,红色线和蓝色线之间的距离很远,这表明进程之间的队列消息传输花费了很长时间。
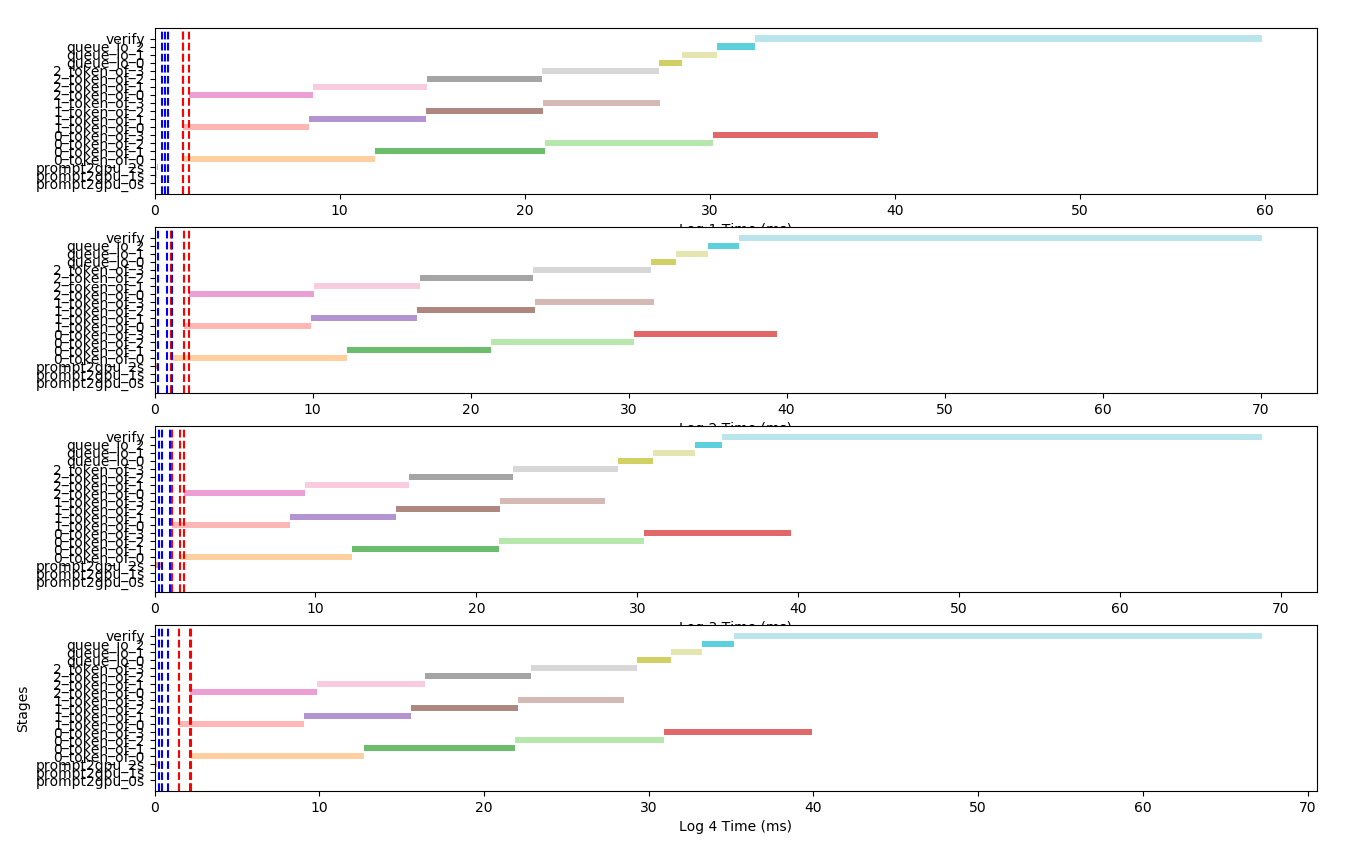
经过检查发现原因是每次投机推理迭代在队列中传递了小模型…这是造成进程间通信缓慢的原因。于是将加载小模型的过程放在小模型进程中而不是每次都传递小模型,timeline如下:
可以看到蓝色线和红色线之间的距离很短,进程间通信时间已经缩短到数ms,不再是性能瓶颈。
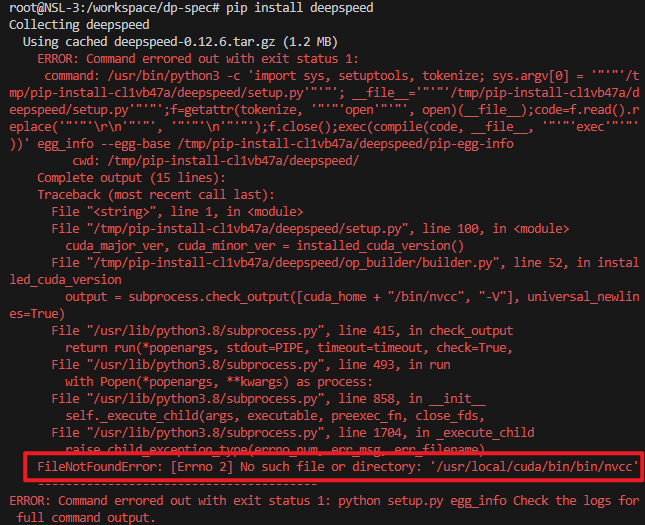
使用DeepSpeed单机多卡推理 安装问题 安装DeepSpeed时出现了一个小插曲,直接使用pip install deepspeed会报错:
注意到是找不到nvcc路径。我检查了环境变量发现CUDA_HOME的值是/usr/local/cuda/bin,猜想应该是安装时读取CUDA_HOME 然后直接拼凑/bin/nvcc…
经过尝试编辑~/.bashrcCUDA_HOME不能改成export CUDA_HOME=/usr/local/cuda/bin:/usr/local/cuda这种形式,想改成这种形式主要是为了避免别的程序出问题。于是最后只好作罢,老老实实把CUDA_HOME改成/usr/local/cuda,然后将Path改成export PATH=$PATH:$CUDA_HOME/bin。source ~/.bashrc之后安装成功。
由于DeepSpeed加载模型权重的策略是:将一个模型权重文件重复加载到4块GPU上,在张量并行时只使用相应的部分。4块RTX 3090加载OPT-6.7b模型时就会出现OOM,故不再使用DeepSpeed做并行推理 。
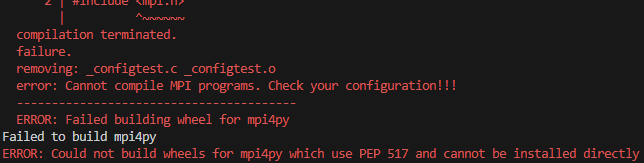
多卡问题 使用多卡需要安装mpi4py,直接pip遇到如下报错
只需要首先
再
即可
SpecInfer-安装 之前提了一个flexflow的#1301 ,作者说最新版解决了问题,正好想写一个从源码构建的说明,于是就从源码构建一边。
首先选择正确的分支与tag(inference分支与24.1.0tag)
克隆仓库。如果是在本地windows克隆仓库再复制到服务器上,就要使用dos2unix命令转换换行符格式
1 find /workspace/FlexFlow/ -type f -exec dos2unix {} \;
按照下述过程进行构建,注意整个过程要在vpn环境下进行。
1 2 3 4 mkdir buildcd build
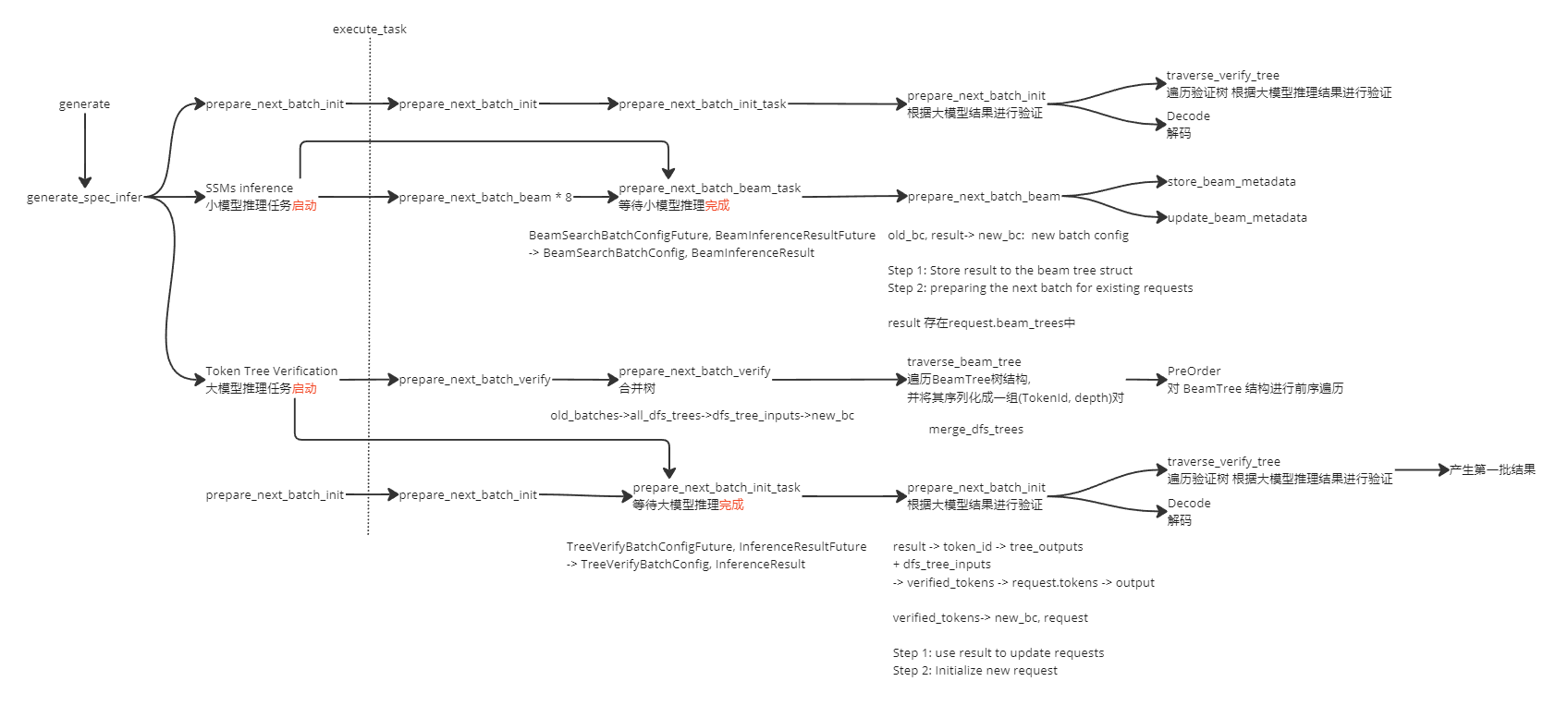
SpecInfer源码研读 由于自己实现的系统与SpecInfer产生的结果有较大差异,而且按照SpecInfer论文中的伪代码实现并不能得到正确的结果,于是研读SpecInfer源码,看其如何实现验证模型对于小模型产生token的接受与拒绝。
prepare_next_batch_verify 猜测是在进行将小模型的所有output转成 new_bc 具体有什么区别?
输入是old_batches vector<BeamSearchBatchConfig>
输出是new_bc TreeVerifyBatchConfig
committed_tokens:用于跟踪每个请求中已经处理过的令牌。这个数据结构是一个映射(map),其中键是请求的唯一标识符(GUID),值是一个向量,存储了每个令牌的绝对深度和在结果中的索引(是request中的第几个token)。 committed_tokens[guid].emplace_back(abs_depth, result_index);
traverse_verify_tree 函数中,verifiedTree和new_committed_tokens有什么区别? 验证通过 与 已提交??
代码分段解析 1 2 3 4 5 6 7 8 9 10 11 12 const std::lock_guard<std::mutex> lock(request_queue_mutex);if (verbose) {"\n############### prepare_next_batch_init ###############\n" ;"\n############### prepare_next_batch_init ###############\n" ;1 : use result to update requests0 ;int result_index = 0 ;
这段代码主要干了两件事:
获取请求队列的锁,用于互斥访问请求队列。
初始化新一批次的配置new_bc。包括:
加锁后,打印日志表示进入准备新批次数据的逻辑
新批次配置new_bc中令牌数num_tokens初始化为0
设置新批次配置的模型ID
result_index变量初始化为0,用于遍历结果集
获取请求队列锁是为了确保线程安全,在更新请求队列、生成新批次配置时,互斥访问和修改数据。初始化new_bc是准备新一轮批次配置的基础工作,先构造一个空的、干净的批次配置,后面将在这个基础上逐步填充新一轮的请求信息、令牌信息。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 for (int i = 0 ; i < BatchConfig::max_requests_per_batch(); i++) { // 批次中request的最大数量是 BatchConfig::max_requests_per_batch()if (old_bc.request_completed[i]) {continue ;"[ " << guid << " ]" << std::endl;from resultint >> tree_outputs =int >>();assert (old_bc.num_tokens > 0 );if (committed_tokens.count(guid) == 0 ) {else {all the tokens that belong to request i1 根节点的绝对深度为0 int root_abs_depth = request.tokens.size() - 1 ;print () << "request.tokens.size(): " << request.tokens.size(); print () << "old_bc.num_tokens: " << old_bc.num_tokens;
这个for循环对旧批次old_batch中的每个请求进行处理。
这段代码的主要逻辑是:对旧批次中的每个请求,初始化一些变量,为后面处理验证tokens做准备。主要的是遍历旧批次所有请求,跳过已完成的请求,获取未完成请求的guid及详细信息Request,清空committed_tokens,初始化tree_outputs等等。
tree_outputs: 用于存储每次从模型推理结果中获取的、针对当前request的验证通过的token。它是当前request本轮要新加入到请求序列中的token。
committed_tokens: 用于存储每次请求中历史累计的全部验证通过的token。与tree_outputs不同,它不是当前轮新的token,而是记录了该request从一开始到当前timestep,所有验证过的token的一个历史累加。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 // 一次while 循环处理一个token 其实就是遍历old_bc中的所有tokenwhile (result_index < old_bc.num_tokens &&id int abs_depth = old_bc.tokensInfo[result_index].abs_depth_in_request;int token_id = result.token_ids[result_index];if (request.status == Request::PENDING) { // 请求PENDING表示请求还没有进行首轮处理 所以跳过tree_outputselse if (abs_depth >= root_abs_depth) {1 );if (verbose) {"Index within old batch: " << result_index << std::endl;" Input: [%d] %d ---> [%d] %d \n" ,"Index within old batch: " << result_index << std::endl;" Input: [%d] %d ---> [%d] %d \n" ,
代码主要逻辑:
在结果result中遍历属于当前请求i的所有token
获取token的depth和id
根据请求状态做不同处理:
如果请求pending, 将token加入committed_tokens
如果depth合法(>= root depth),则同时将token放入tree_outputs和committed_tokens
打印验证通过的token信息
result_index递增,处理下一token
可以看到,对于验证通过的token,同时将其放入tree_outputs和committed_tokens两个结构中。tree_outputs存储新增加的待提交token。committed_tokens存储历史所有验证过的token。关键在于使用token的depth,与请求中root depth比较,进行token验证。 depth合法的token才会被验证通过,加入两个结构待后续处理。
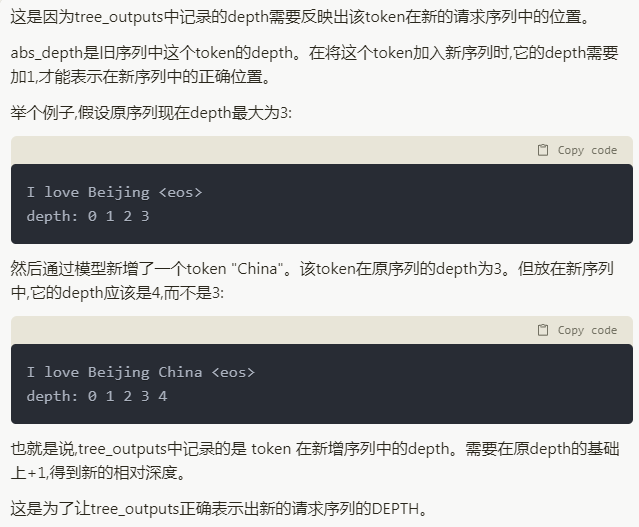
注意tree_outputs.emplace_back(token_id, abs_depth + 1); 这里存储abs_depth+1的原因,这是claude 2给出的解释:
注意 这段代码执行过后,tree_outputs和committed_tokens已经被填满了。
1 2 3 4 5 if (request.status == Request::RUNNING) {int >> verified_tokens =print ("Number of Verified Tokens = %zu" ,
这部分逻辑是 Request状态为RUNNING, 表示这是一个进行中的request。
当请求运行中时,对本轮新增的token(tree_outputs)调用 traversal_verify_tree 函数进行进一步验证:
将 guid, dfs_tree_inputs, tree_outputs作为输入参数传递给traversal_verify_tree函数
traversal_verify_tree会基于这些信息,构建一棵树,然后进行深度优先遍历,对token进行验证
它会返回一个verified_tokens数组,包含所有通过验证的 token
然后打印出verified_tokens的数量
所以这部分逻辑主要作用是:对正在运行中的 Request,使用树形算法验证 model 本轮生成的新 token。获取验证通过的 tokens,后面用于更新 Request的状态。
注意这里在函数traversal_verify_tree中又进行了一次验证 ,之前不是说tree_outputs中存储的已经是验证后的结果了吗?
这是由于之前的验证只是从depth维度验证了token的正确性,这里traversa_verify_tree函数才是真正的验证过程。
于是我们定位到验证的代码位置:函数traversal_verify_tree()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 std::vector<std::pair<BatchConfig::TokenId, int >>int >> constint >> constint >> verifiedTree;0 ));int , int >> new_committed_tokens =int , int >>();print ("Input tree size (%zu) Output tree size (%zu)" ,is the dfs_tree_inputs_map[guid] array og (token id ,for (auto const &pair : inputSerializedTree) {" " << pair.second << ":" << pair.first;print ("(%d, %d)" , pair.first, pair.second);print ("Input tree:%s" , oss.str ().c_str());print ("========Output============" );is an array of (token id , depth + 1 ) pairsfor (auto const &pair : outputSerializedTree) {print ("(%d, %d)" , pair.first, pair.second);" " << pair.second << ":" << pair.first;print ("Output tree:%s" , oss.str ().c_str());print ("========Committed============" );is an array of (depth, result_index) pairs for for (auto const &pair : committed_tokens.at(guid)) {print ("(%d, %d)" , pair.first, pair.second);" " << pair.second << ":" << pair.first;print ("Committed tokens:%s" , oss.str ().c_str());'s safe to have inputSerializedTree.size() > outputSerializedTree.size() // In this case the inputSeriedTree ends with padding 0s assert(inputSerializedTree.size() >= outputSerializedTree.size()); for (int i = 0; i < outputSerializedTree.size(); i++) { auto input = inputSerializedTree.at(i); auto output = outputSerializedTree.at(i); if (i == 0) { verifiedTree.push_back(output); new_committed_tokens.push_back(std::make_pair( input.second, committed_tokens.at(guid).at(i).second)); // <input_abs_depth, // input_index_in_batch> // std::cout << committed_tokens.at(guid).at(i).first << ", " // << committed_tokens.at(guid).at(i).second << std::endl; // std::cout << input.first << ", " << input.second << std::endl; assert(committed_tokens.at(guid).at(i).first == input.second); continue; } if (input.first == verifiedTree.back().first && input.second == verifiedTree.back().second) { verifiedTree.push_back(output); new_committed_tokens.push_back(std::make_pair( input.second, committed_tokens.at(guid).at(i).second)); // <input_abs_depth, // input_index_in_batch> assert(committed_tokens.at(guid).at(i).first == input.second); } } committed_tokens[guid] = new_committed_tokens; { log_req_mgr.print("========Verified============"); std::ostringstream oss; for (auto const &pair : verifiedTree) { // log_req_mgr.print("(%d, %d)", pair.first, pair.second); oss << " " << pair.second << ":" << pair.first; } log_req_mgr.print("Verified:%s", oss.str().c_str()); } { log_req_mgr.print("========New Committed============"); std::ostringstream oss; for (auto const &pair : committed_tokens.at(guid)) { // log_req_mgr.print("(%d, %d)", pair.first, pair.second); oss << " " << pair.second << ":" << pair.first; } log_req_mgr.print("New committed:%s", oss.str().c_str()); } return verifiedTree; }
验证逻辑的关键点
每个token pair都有一个token ID和一个深度值。
第一个token总是被验证,因为它是由模型推理生成的。
后续token的验证基于它们是否与之前验证的token在输入树上有相同的父节点。这是通过检查当前token pair是否与 verifiedTree 中最后一个token pair具有相同的ID和深度来确定的。
如果当前token pair通过了这个检查,它就被认为是经过验证的,并且被添加到 verifiedTree 中。
与此同时,相关的 committed_tokens 信息也被更新,以反映这个已经验证的token。
vllm add a new model 首先来看OPTDecoder的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 class OPTDecoder (nn.Module):def __init__ (self, config: OPTConfig ):super ().__init__()if config.word_embed_proj_dim != config.hidden_size:False )else :None if config.word_embed_proj_dim != config.hidden_size:False )else :None if config.do_layer_norm_before and not config._remove_final_layer_norm:else :None for _ in range (config.num_hidden_layers)])
project_out, project_in 以前没见过,学习记录一下。GPT的回答:
在这段代码中,project_in和project_out是两个可选的全连接(Linear)层,它们的目的是在处理嵌入(embedding)向量时进行维度转换。这两个层的使用取决于词嵌入向量的维度(config.word_embed_proj_dim)与模型隐藏层的大小(config.hidden_size)是否相等。具体来说:
project_inconfig.word_embed_proj_dim调整到模型的隐藏层大小config.hidden_size。这个转换发生在词嵌入向量被送入解码器层之前,确保了嵌入向量的大小与解码器层期望的输入尺寸一致。只有当config.word_embed_proj_dim不等于config.hidden_size时,这个层才会被创建和使用。project_outconfig.hidden_size调整回config.word_embed_proj_dim。这主要是为了使模型输出与词汇表大小的预测向量对齐,特别是在进行语言模型预测时。与project_in类似,这个层也只有在config.hidden_size不等于config.word_embed_proj_dim时才会被创建和使用。
这种设计允许模型在内部处理时使用一个不同的维度(通常是更大的隐藏层维度),而在模型的输入和输出侧与词嵌入层保持一致的维度。这可以增加模型处理的灵活性和效率,尤其是在嵌入层的维度较小,而内部隐藏层需要较大维度以捕获更复杂特征时。
final_layer_norm这段代码的目的是处理模型中最后一个层归一化(Layer Normalization)的条件创建。它根据配置参数决定是否在OPTDecoder中加入一个最终的层归一化(final_layer_norm)。这里主要涉及两个配置选项:
config.do_layer_norm_beforeTrue,则通常需要在模型的最后也应用一个层归一化,以保持一致性。config._remove_final_layer_normFalse(即不移除最终的层归一化),并且do_layer_norm_before为True,那么将在模型末尾添加一个层归一化。否则,如果这个标志为True(表示移除最终的层归一化)或者do_layer_norm_before为False,则不添加这个层归一化。
具体来说,这段代码通过判断条件if config.do_layer_norm_before and not config._remove_final_layer_norm来决定是否创建self.final_layer_norm:
如果条件为True,则创建一个nn.LayerNorm实例,其归一化是在模型的隐藏维度config.hidden_size上进行的,且根据config.layer_norm_elementwise_affine参数决定是否包含可学习的仿射参数。
如果条件为False,则不创建这个层归一化,即self.final_layer_norm = None。
这样做的目的是为了保证即使在新版本的模型架构中,也能兼容和正确使用旧版本训练的模型检查点。
cache_events 这段代码是在一个循环中遍历OPTDecoder的所有解码器层(self.layers),对输入的hidden_states进行逐层处理。在这个过程中,它还考虑了cache_events,这是一个与每一层相关联的可选参数列表,用于控制特定于硬件的优化行为,比如在使用GPU时的异步计算事件。
cache_eventscache_events的目的是提供一个同步机制(例如,CUDA事件),这些事件可以用来优化并行计算的性能,特别是在涉及到大量数据传输和复杂计算的情况下。通过等待特定的事件完成,模型可以更有效地管理资源和计算,避免不必要的等待和数据竞争。
在这段代码中:
循环开始遍历每一层解码器(for i in range(len(self.layers)))。
检查cache_events是否为None。如果是,表示没有提供事件同步机制,将cache_event设置为None。如果不是,那么它会从cache_events列表中获取当前层对应的事件(cache_event = cache_events[i])。
获取当前层的实例(layer = self.layers[i])。
使用当前层处理hidden_states,并将处理结果用于下一层的输入。这个步骤中,如果提供了cache_event,它将被传递给当前层,允许层在执行其操作时利用这个事件进行同步或优化。
这种设计使得OPTDecoder可以在执行解码操作时,利用硬件特性(如GPU的异步执行能力)来提高运行效率和性能。