gpt-fast
本文最后更新于:2 个月前
GPT-fast
偶然发现Pytorch官方在2023年11月30号写了这个blog:https://pytorch.org/blog/accelerating-generative-ai-2/
使用不到1000行pytorch原生代码实现针对大语言模型推理加速,于是拿来学习一番。
github仓库地址:https://github.com/pytorch-labs/gpt-fast
该项目主要从以下四个方面进行LLM推理加速:
- Torch.compile:PyTorch 模型的编译器
- GPU 量化:通过降低精度运算来加速模型
- 推测性解码:使用小型“草稿”模型来预测大型“目标”模型的输出来加速法学硕士
- 张量并行:通过在多个设备上运行模型来加速模型。
想了解具体细节请参照github仓库代码和blog。本文主要记录笔者在学习代码和blog的过程中的心得。
torch.compile
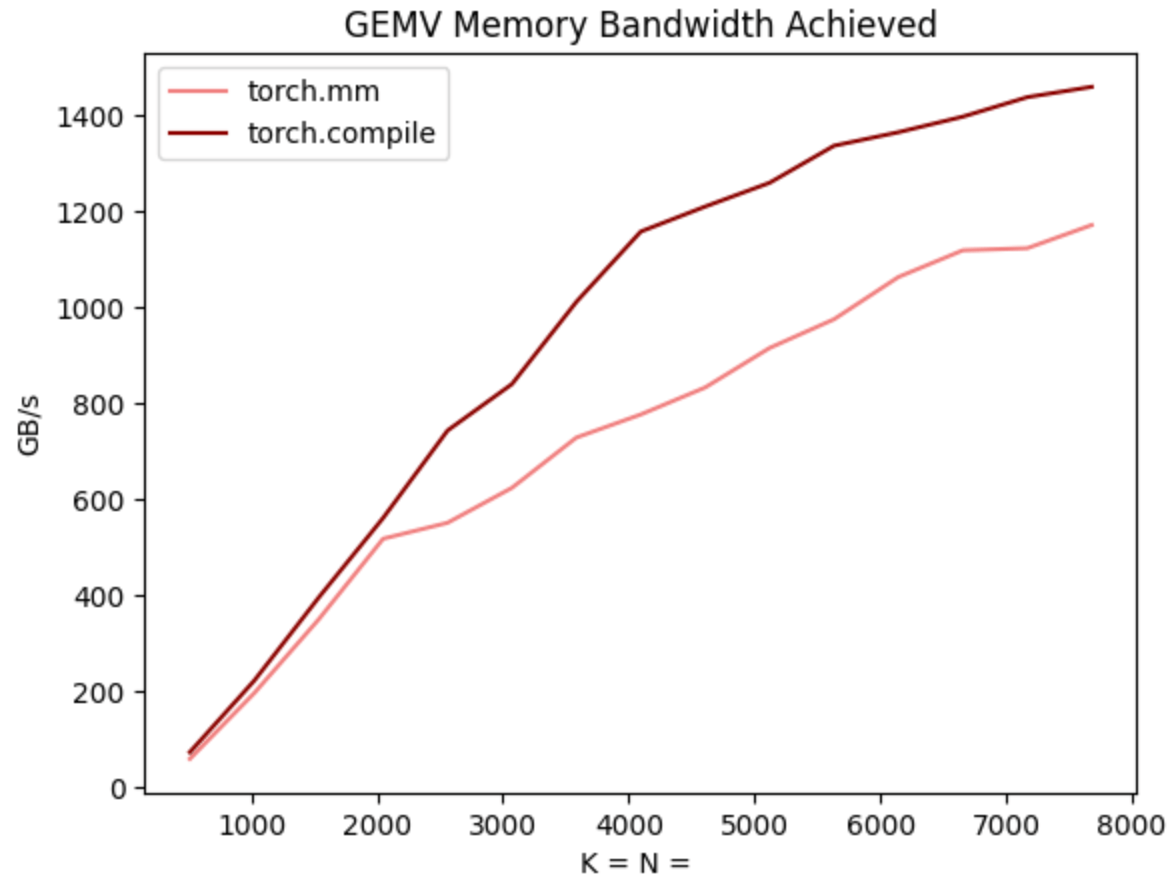
影响torch.compile性能的因素主要有两个:
降低CPU分发任务的开销。其中最有效率的方法之一是 CUDAgraphs。
torch.compile生成了更快的kernels,包括矩阵乘法和attention,blog中说比flashattention2和CuBLAS更快。这可能难以置信,但其实是由于BS=1时,如果加上KVcache优化,每次矩阵乘法其实是一个矩阵向量乘法。这意味着torch.compile完全可以写出比专注于优化矩阵乘法的CuBLAS更快的算子。

int8量化
量化究竟是如何加速推理的?思考能否进一步加速推理的的一种方法是计算我们与理论峰值的接近程度。 在这种情况下,最大的瓶颈是将权重从 GPU 显存加载到寄存器的成本。 换句话说,每次前向传递都要求我们“接触”GPU 上的每个参数。 那么,理论上我们能够以多快的速度“触及”模型中的每个参数?
为了衡量这一点,我们可以使用模型带宽利用率(MBU)。 这衡量了我们在推理过程中能够使用的内存带宽的百分比。
MBU的计算公式如下:简单理解,由于每得到一个token就相当于前向传播一次,就是访问一次所有的参数,就可以得到下面这个公式。

例如,假设我们有一个 7B 参数模型。 每个参数都存储在 fp16 中(每个参数 2 个字节),我们实现了 107 个令牌/秒。 最后,我们的 A100-80GB 理论内存带宽为 2 TB/s。 将所有这些放在一起,我们得到 **72% MBU! **这相当不错,考虑到即使只是复制内存也很难突破 85%。
但是……这确实意味着我们非常接近理论极限,并且我们显然在从内存加载权重方面遇到了瓶颈。 我们可能只能再争取 10% 的性能。让我们再看一下上面的等式。 我们无法真正改变模型中参数的数量。 我们无法真正改变 GPU 的内存带宽(好吧,不花更多钱)。 但是,我们可以更改每个参数存储的字节数!

于是有了下面的图:
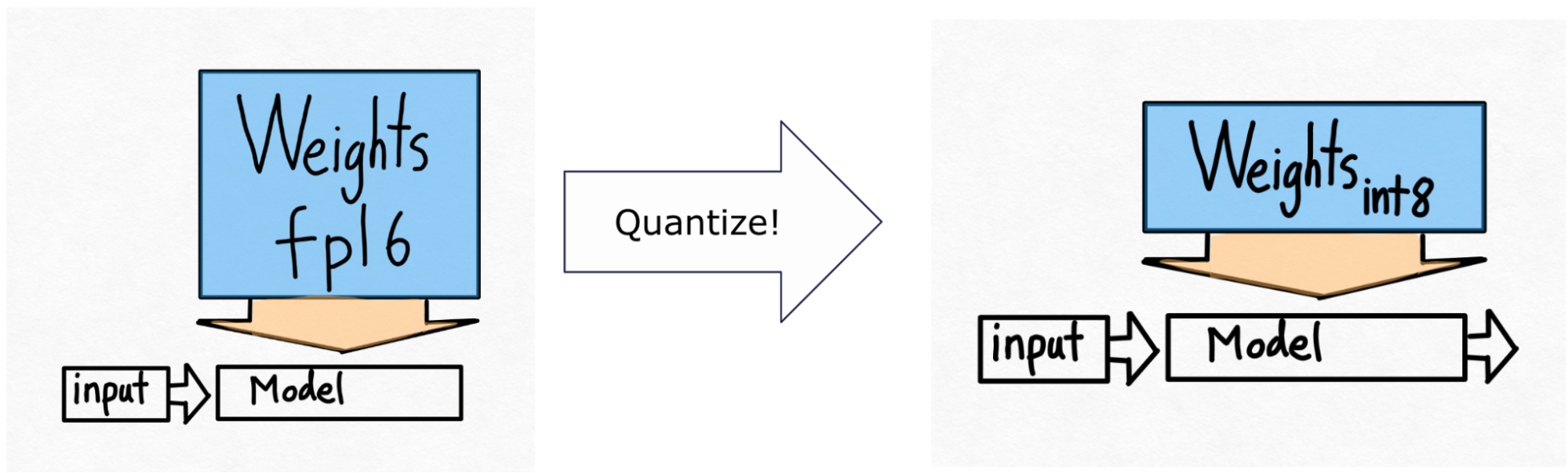
这仅量化权重 - 计算本身仍然在 bf16 中完成。 这使得这种形式的量化易于应用,并且精度几乎没有降低。
投机推理
int4量化
虽然推理速度更快,但是模型的精度开始出现下降,成为一个问题。
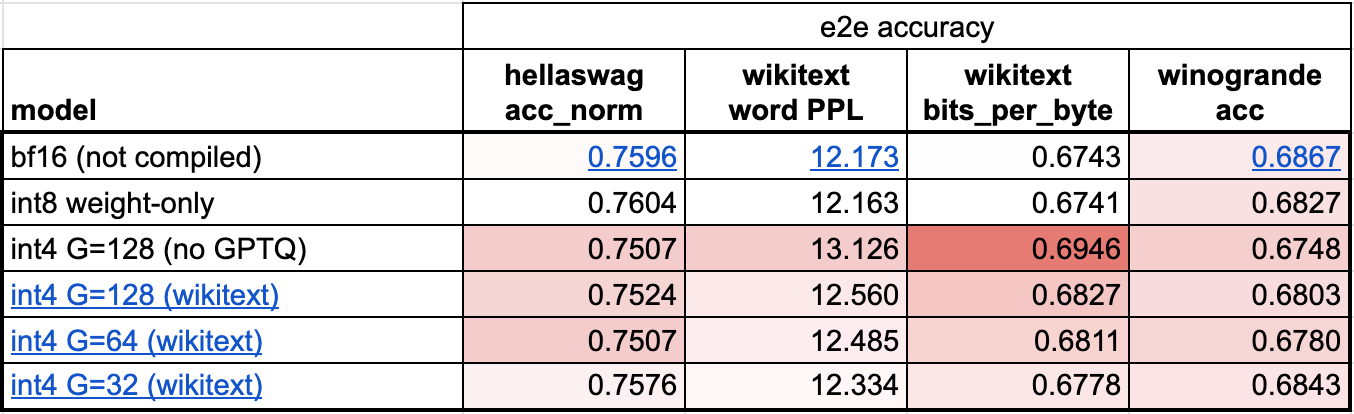
当我们进行量化时,我们将原始的浮点张量中的值映射到整数值。缩放因子在这里起到重要的作用,它用于确定如何映射这些值。
使用两个技巧限制int4精度的下降:
- 使用更细粒度的缩放因子。