LLM-with-fine-tuning-and-RAG
本文最后更新于:2 个月前
一些知识
LLM处理长文本
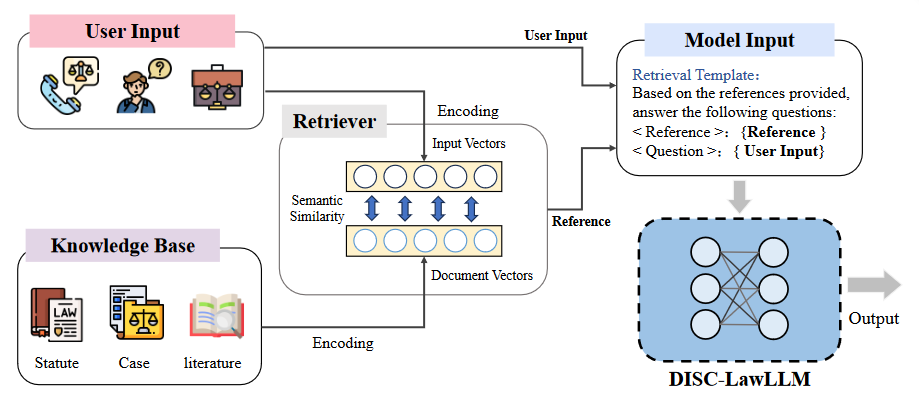
有一个知识库 (Knowledge Base),用户输入时将用户的输入与knowledge base进行向量匹配(信息检索),结果称为reference,再将reference和user input一并送入model input,这样可以大大减少送入model input的输入长度,reference中只包括知识库中与用户输入有关的知识。
这里知识库有预处理,把知识库切成若干段,只将少量的和问题有关的片段拿出来,放到大模型的输入里,这就将“大模型外挂数据库”的问题变成了“文本检索”问题,目标是根据问题找出文档中和问题最相关的片段。
LLM推理结果不准确
两个挑战
- no source
- out of dat
RAG(retrieval-Augmented)Generation
嵌入(embedding)是text的向量表示(vector representation)
如何使用RAG
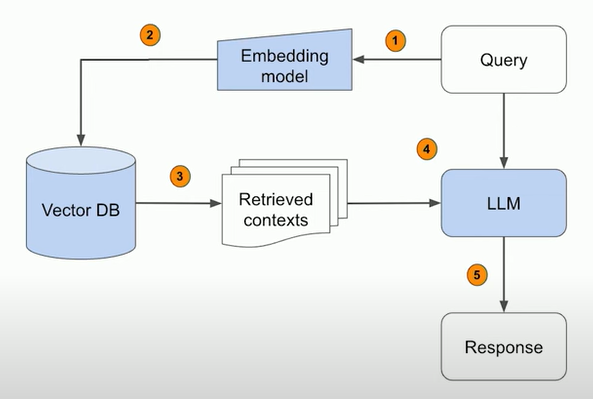
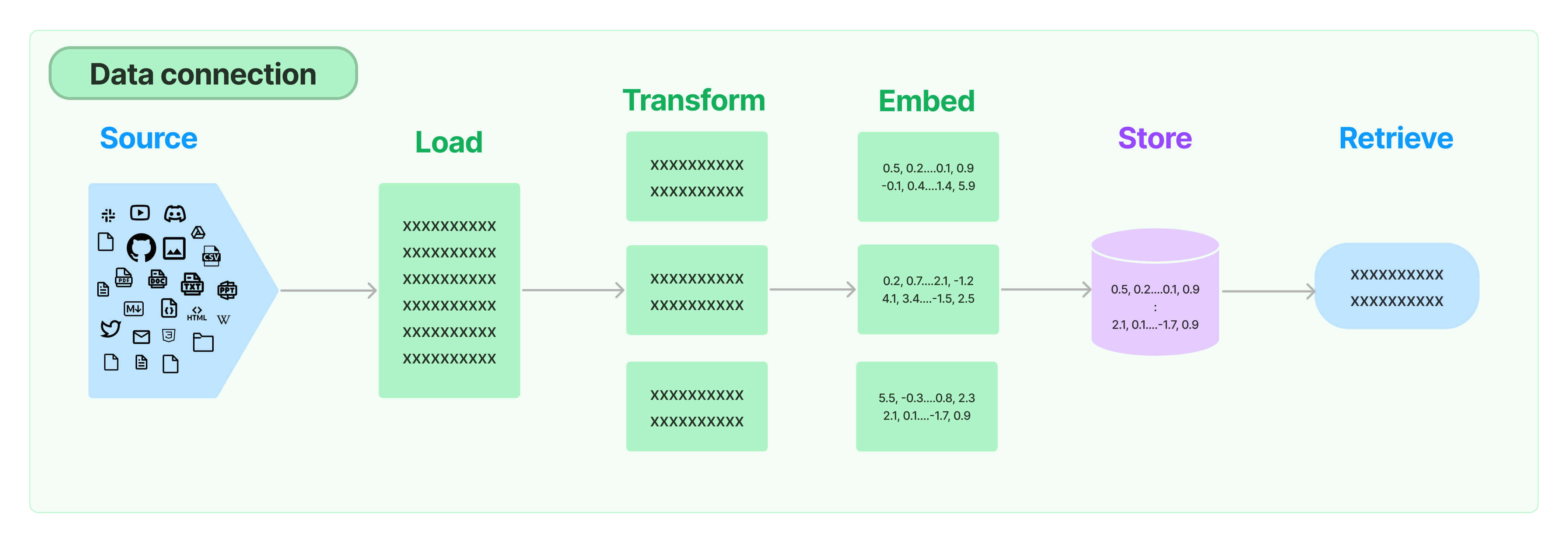
langchain中的retrieval主要包括以下几个模块:
- Document loaders:LangChain 提供了从所有类型的位置(私有 S3 存储桶、公共网站)加载所有类型文档(HTML、PDF、代码)的集成。
- Text splitting:LangChain: 提供了多种转换算法来执行此操作,以及针对特定文档类型(代码、Markdown 等)优化的逻辑。
- Text embedding models:嵌入捕获文本的语义,使您能够快速有效地找到文本的其他相似部分。LangChain 提供与超过 25 种不同嵌入提供商和方法的集成,从开源到专有 API,让您可以选择最适合您需求的一种。 LangChain提供了标准的接口,让您可以轻松地在模型之间进行切换。
- Vector stores:随着嵌入的兴起,需要数据库来支持这些嵌入的高效存储和搜索。 LangChain 提供与 50 多种不同矢量存储的集成,从开源本地矢量存储到云托管专有矢量存储,让您可以选择最适合您需求的一种。
- Retrievers:LangChain支持多种不同的检索算法,最基本的是简单语义搜索。
- Indexing:LangChain Indexing API 将您的数据从任何来源同步到向量存储中。
youtube上一个视频进行retrieval的过程:
- prepare the data (turn your data into a vector database)
- 加载数据文件from langchain 读取到python中 如.md文件 .pdf文件等
- 使用langchain中的TextSplitter类 split每一个document into chunks
- chunk[i].page_content:这一个chunk中的字符内容
- chunk[i].metadata:这个chunk所属的源文件的路径,以及startindex
- 将document转换成database,如ChromaDB,把vector embeddings作为key
- 使用Chroma.from_ducoments()方法 needs OpenAI account,因为需要OpenAI embedding functions to生成每一个chunk的enbedding
- langchain中的evaloator可以计算两个embedding的距离
- query for relevant data
- 对prompt进行embedding编码,采用与处理database一样的方式。然后从database中选出几个得分较低(相似度较高)的chunk,
- craft the response
一个误区
- embedding_function = OpenAIEmbeddings() vector = embedding_function.embed_query(“apple”)
- tokenizer = AutoTokenizer.from_pretrained(“/models/opt-13b”) vector = tokenizer.encode(“apple”)
这两者是不同的。
嵌入维度: OpenAIEmbeddings 返回的 vector 通常是一个具有较高维度的实数向量,其中包含了模型对 “apple” 语义的深层次理解。而 Hugging Face Transformers Tokenizer 返回的 vector 是一个整数编码,代表 “apple” 在模型的词汇表中的位置。
开源框架
llama-index
由于无法访问openai,故采用github上的Replicate方式,使用Replicate的时候需要登录,获取REPLICATE_API_TOKEN并在代码里设置。虽然成功加载了本地知识库(一些pdf文件),但好像还是部署在云端的大模型。考虑一种使用本地model和tokenizer的方式。
issue中存在下面的示例代码,但仅仅在import步骤就出现了ModuleNotFoundError: No module named ‘openai.openai_object’报错,故考虑查看issue中my own llm关键词。
有位老哥说自己用llama-7b-hf+GPTListIndex成功了
使用示例代码,出师不利:
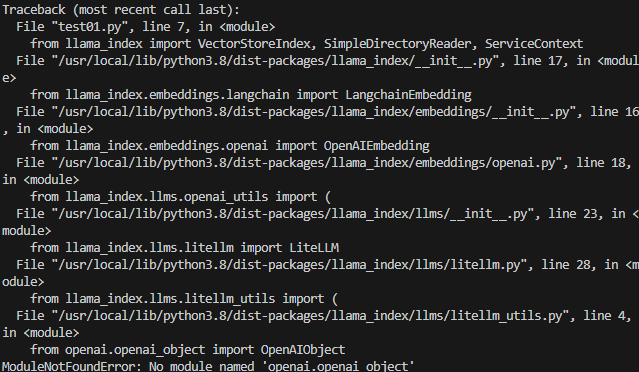
经过搜索issue,发现是llama-index版本太低了…离谱的是我直接pip install llama-index安装的竟然不是最新版本…
经过一番波折发现,llama-index默认的llm和embedding model都是使用的OpenAI的接口,我希望使用自己的LLM和Embedding模型,找了找文档竟然没有示例代码…于是写了下面代码走流程
1 | |
虽然可以运行,但问题出在虽然指定了device_map=”auto”,还是使用cpu进行推理,device=0我的单卡3090又放不下。又看到说langChain只支持单卡加载
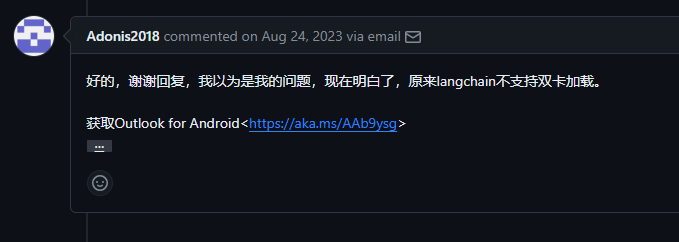
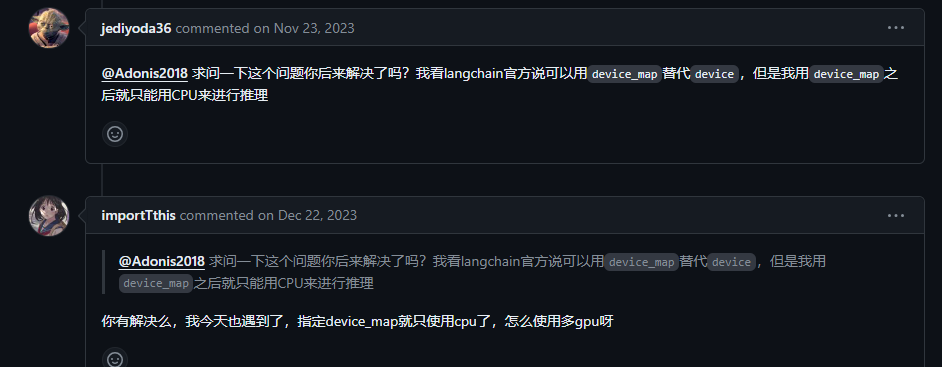
搜索中又看到一片博客

