MoE学习笔记
本文最后更新于:2 个月前
MoE特点总结
混合专家模型 (MoEs):
- 与稠密模型相比, 预训练速度更快
- 与具有相同参数数量的模型相比,具有更快的 推理速度
- 需要 大量显存,因为所有专家系统都需要加载到内存中
- 在 微调方面存在诸多挑战,但 近期的研究 表明,对混合专家模型进行 指令调优具有很大的潜力。
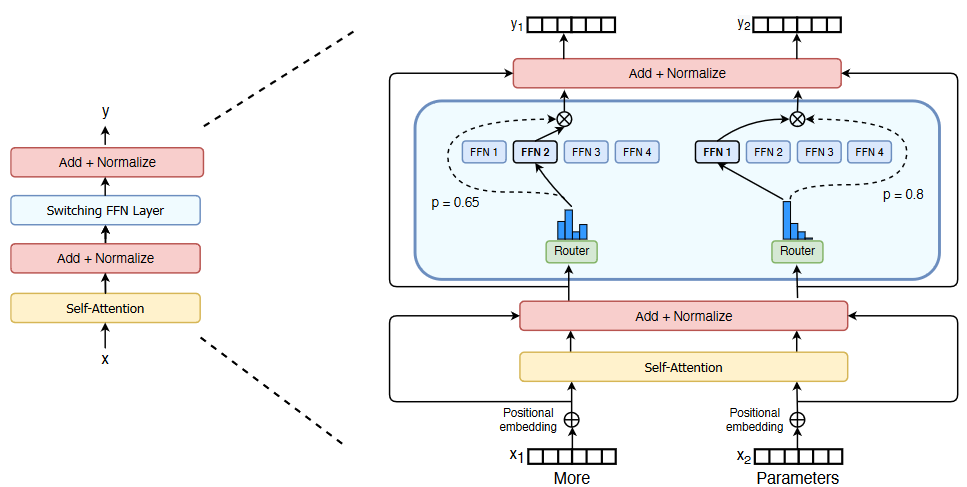
从图中可知,主要包括两部分:
- 稀疏MoE层
- 门控网络or路由
MoE的两个主要挑战
训练挑战: 虽然 MoE 能够实现更高效的计算预训练,但它们在微调阶段往往面临泛化能力不足的问题,长期以来易于引发过拟合现象。
推理挑战: MoE 模型虽然可能拥有大量参数,但在推理过程中只使用其中的一部分,这使得它们的推理速度快于具有相同数量参数的稠密模型。然而,这种模型需要将所有参数加载到内存中,因此对内存的需求非常高。以 Mixtral 8x7B 这样的 MoE 为例,需要足够的 VRAM 来容纳一个 47B 参数的稠密模型。之所以是 47B 而不是 8 x 7B = 56B,是因为在 MoE 模型中,只有 FFN 层被视为独立的专家,而模型的其他参数是共享的。此外,假设每个令牌只使用两个专家,那么推理速度 (以 FLOPs 计算) 类似于使用 12B 模型 (而不是 14B 模型),因为虽然它进行了 2x7B 的矩阵乘法计算,但某些层是共享的。
负载均衡:当数据通过激活的专家时,实际的批量大小可能会减少。比如,假设我们的输入批量包含 10 个令牌, 可能会有五个令牌被路由到同一个专家,而剩下的五个令牌分别被路由到不同的专家。这导致了批量大小的不均匀分配和资源利用效率不高的问题。
在门控网络中加入噪声是为了负载均衡。
- 辅助损失:在MoE训练中,为了避免门控网络倾向于主要激活相同的几个专家,引入了辅助损失,旨在鼓励给予所有专家相同的重要性。
MoE学习笔记
http://example.com/2024/01/31/MoE学习笔记/